Table of contents
- Model Description
- Plugin Name and Description
- GUI and Parameters
- Deploy() method
- Improving the Implementation [Optional]
Unconditional Random Generation
In this demo, we will learn how to unconditionaly generate a random drum loop on a button press.
the source code for this demo is available in the
Demos/MidToMidbranch of the repository.
Model Description
The model we will be using in this exercise is a VariationalAutoEncoder (VAE) trained on the Groove Midi Dataset.
The model has been trained on 2-bar drum loops in 4/4 time signature.
The model has already been serialized and is available at TorchScripts/Models/drumLoopVAE.pt
Input/Output Description
The input and output of the model are both 3 stacked tensors of shape (32, 9) where 32 is the number of 16th notes in a 2-bar segment and 9 is the number of drum instruments. The three stacked tensors are as follows:
hits: A binary tensor indicating whether or not a drum instrument is hit at a given time stepvelocities: A tensor indicating the velocity of the drum instrument at a given time stepoffsets: A tensor indicating the offset of the drum instrument at a given time step
Methods available
The model has multiple methods available, some of which we will be using in this demo. The python definitions of these models are as follows:
1. encode
This method encodes a given input pattern into a latent vector. The method returns a number of parameters, however the third parameter is the latent vector we are interested in.
We will not be using this method until demo 3. A more detailed description of this method will be provided here
2. sample
This method decodes a given latent vector into an output tensor and returns a hits, velocities, and offsets tensors describing the output pattern.
The input to this method requires a number of additional parameters, however, for the purposes of this demo, we will not be discussing them.
def sample(self, latent_z, voice_thresholds, voice_max_count_allowed, sampling_mode: int = 0,
temperature: float = 1.0):
"""Converts the latent vector into hit, vel, offset values
:param latent_z: (Tensor) [N x latent_dim]
:param voice_thresholds: [N x 9] (floatTensor) Thresholds for hit prediction
:param voice_max_count_allowed: [N x 9] (floatTensor) Maximum number of hits to allow for each voice
:param sampling_mode: (int) 0 for top-k sampling,
1 for bernoulli sampling
:param temperature: (float) temperature for sampling
Returns:
h, v, o, _h
"""
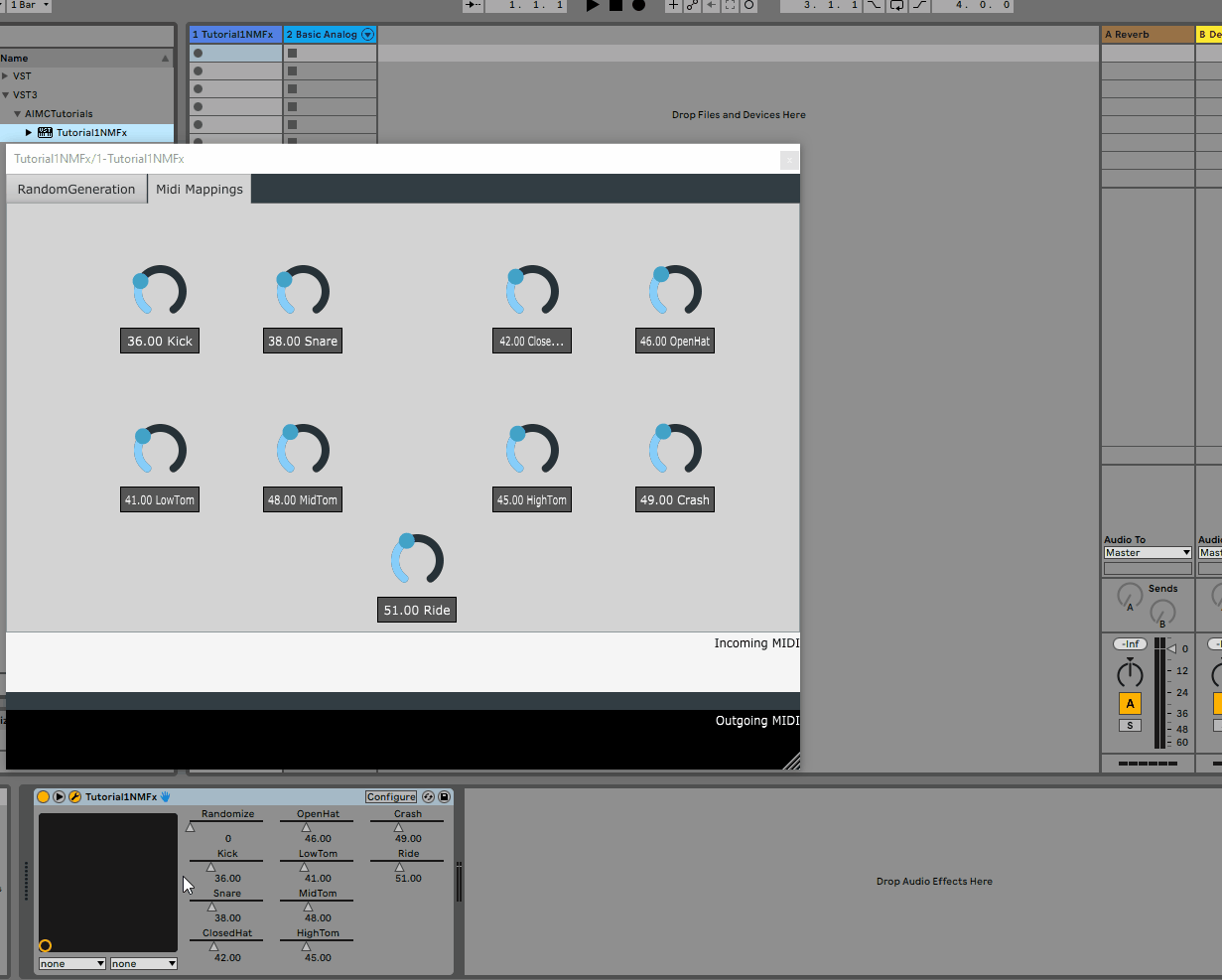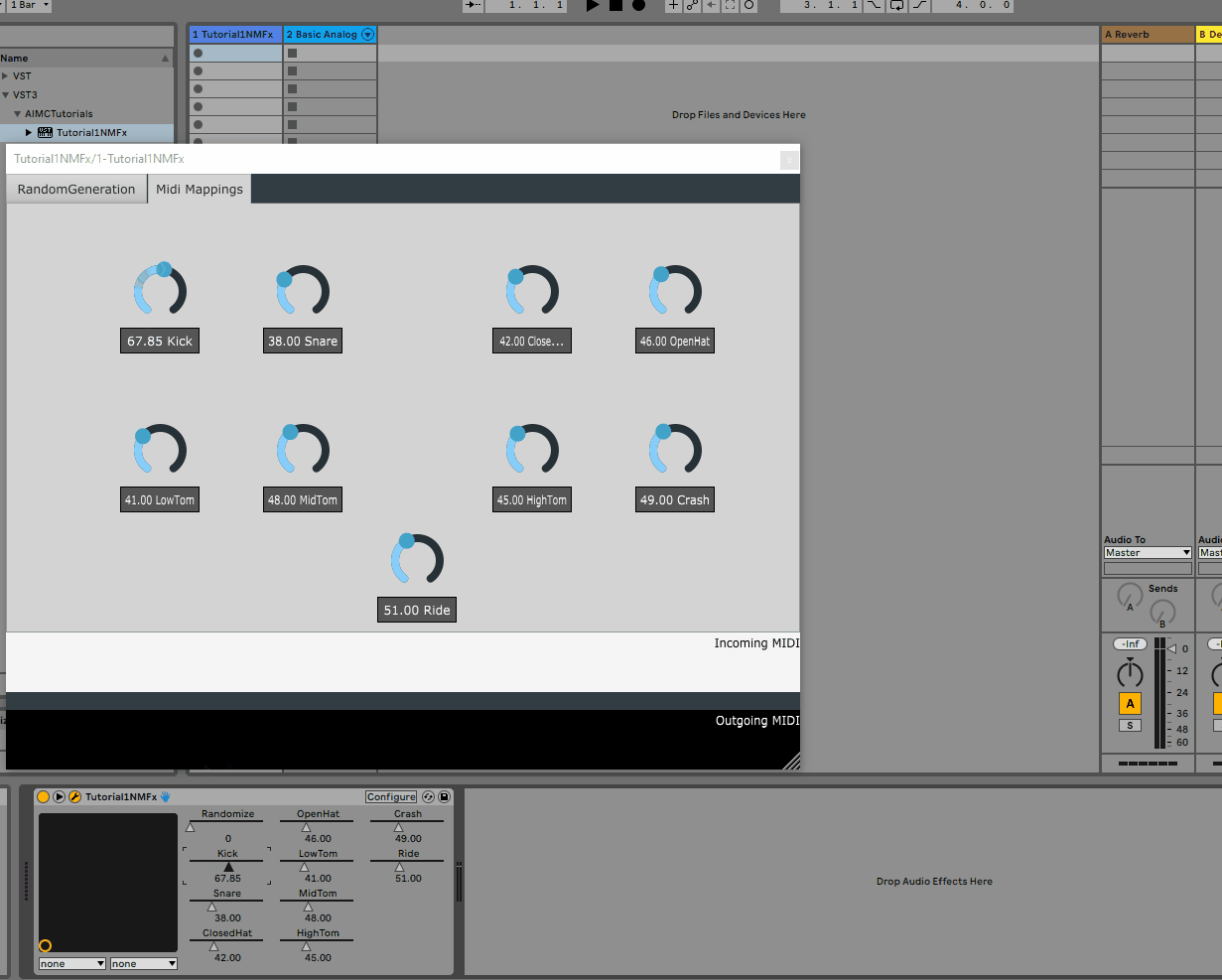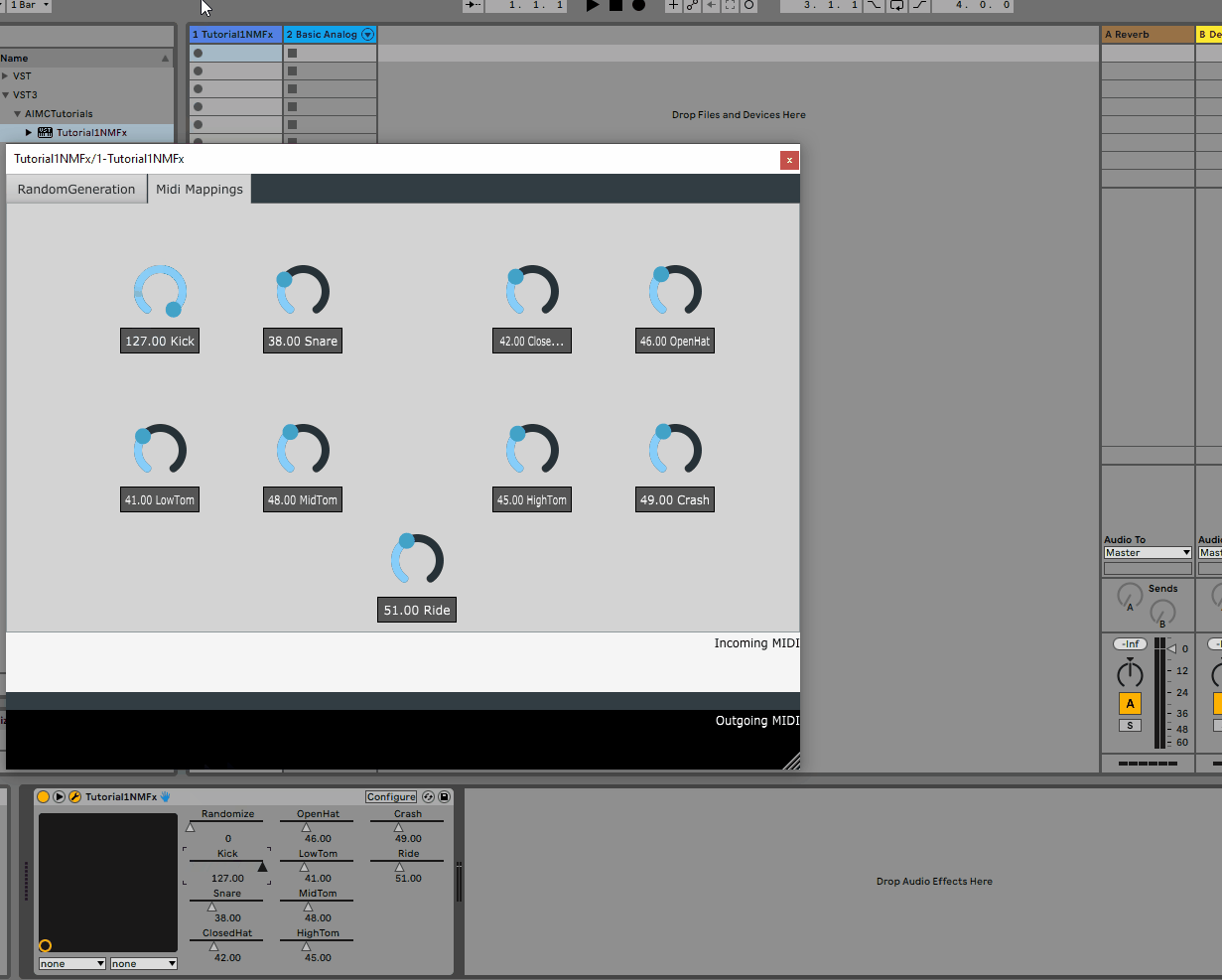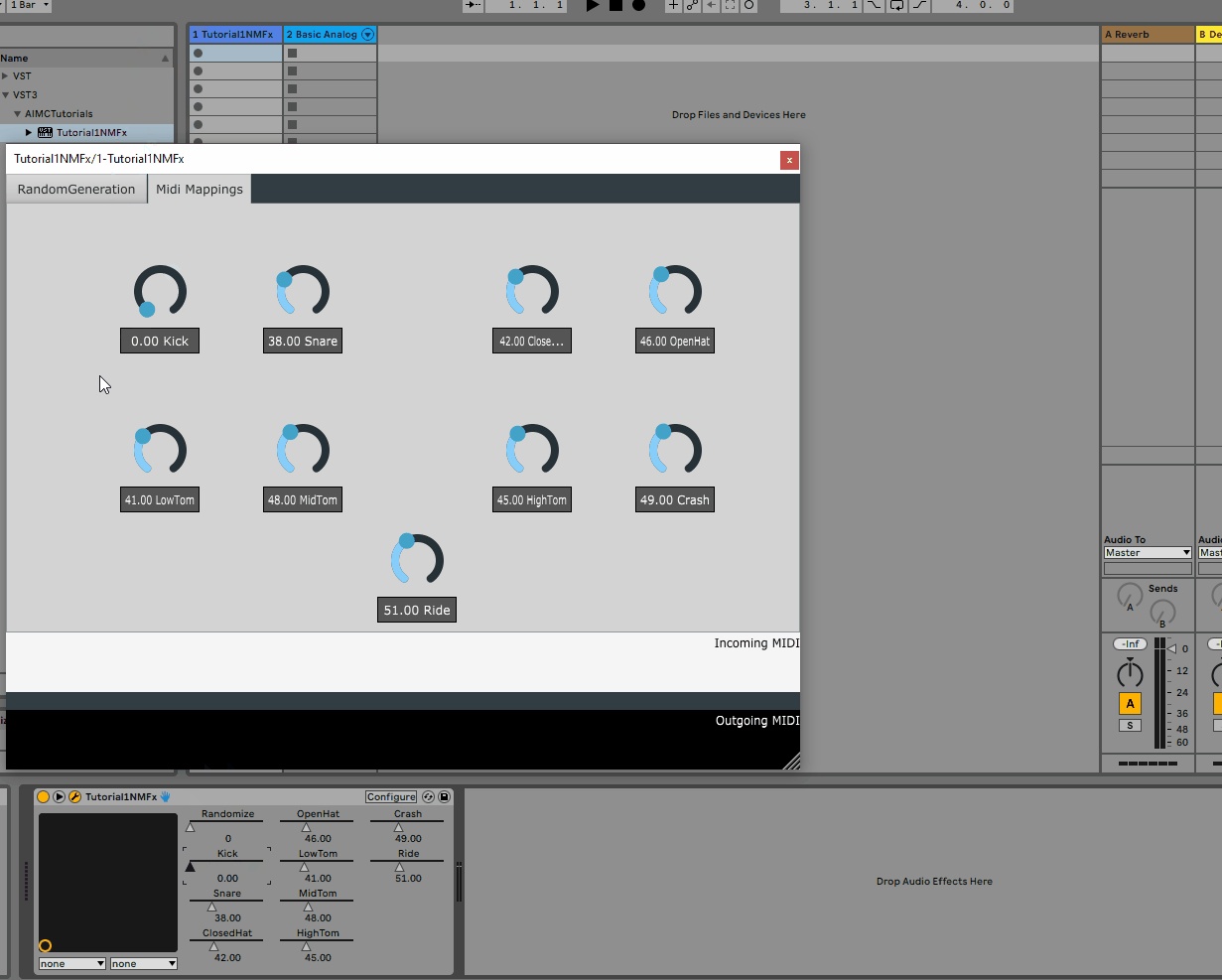
Midi Mappings
The 9 voices of the model are as follows:
| Index | Instrument | Midi Note |
|---|---|---|
| 0 | Kick | 36 |
| 1 | Snare | 38 |
| 2 | Closed HiHat | 42 |
| 3 | Open HiHat | 46 |
| 4 | Low Tom | 41 |
| 5 | Mid Tom | 47 |
| 6 | High Tom | 50 |
| 7 | Crash Cymbal | 49 |
| 8 | Ride Cymbal | 51 |
Plugin Name and Description
As mentioned here, we need to specify the name of the plugin as well as some descriptions for it.
To do this, we will modify the PluginCode/CMakeLists.txt file as follows:
project(Demo1 VERSION 0.0.1)
set (BaseTargetName Demo1)
add_definitions(-DPROJECT_NAME="${BaseTargetName}")
juce_add_plugin("${BaseTargetName}"
# VERSION ... # Set this if the plugin version is different to the project version
# ICON_BIG ... # ICON_* arguments specify a path to an image file to use as an icon for the Standalone
# ICON_SMALL ...
COMPANY_NAME "DemosMid2Mid" # Replace with a tag identifying your name
IS_SYNTH TRUE # There is no MIDI vst3 plugin format, so we are going to assume a midi instrument plugin
NEEDS_MIDI_INPUT TRUE
NEEDS_MIDI_OUTPUT TRUE
AU_MAIN_TYPE kAudioUnitType_MIDIProcessor
EDITOR_WANTS_KEYBOARD_FOCUS FALSE
COPY_PLUGIN_AFTER_BUILD TRUE # copies the plugin to user plugins folder so as to easily load in DAW
PLUGIN_MANUFACTURER_CODE Juce #
PLUGIN_CODE aaaa # MUST BE UNIQUE!! If similar to other plugins, conflicts will occur
FORMATS AU VST3 Standalone
PRODUCT_NAME "Demo1") # Replace with your plugin title
Once you re-build the cmake project, and re-build the plugin, you should see the name of the plugin change in the DAW:
Now we are ready to move on to the next step.
GUI and Parameters
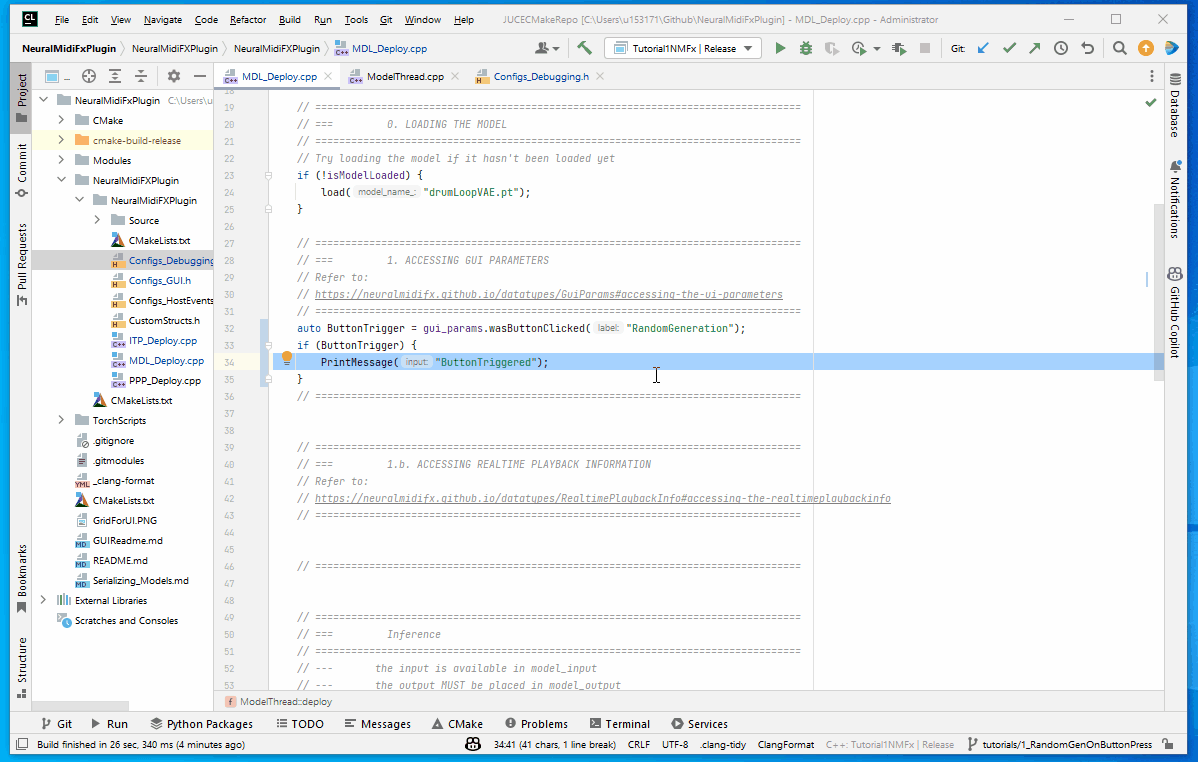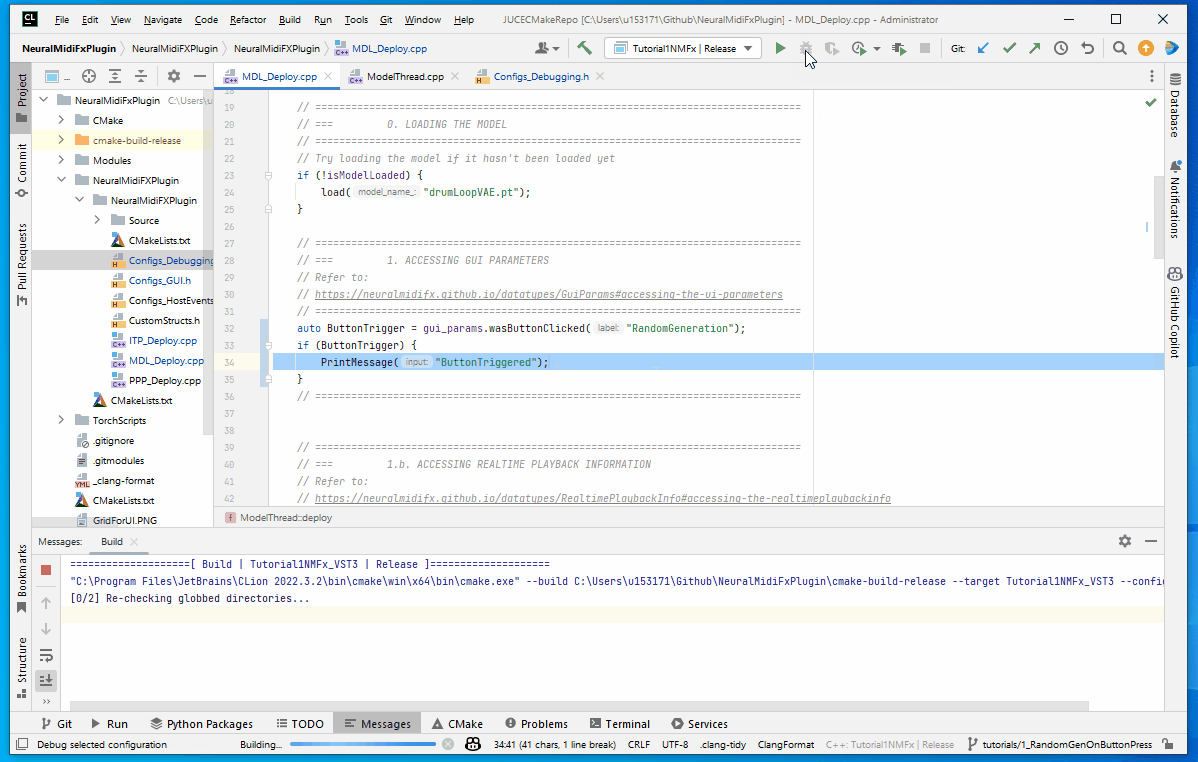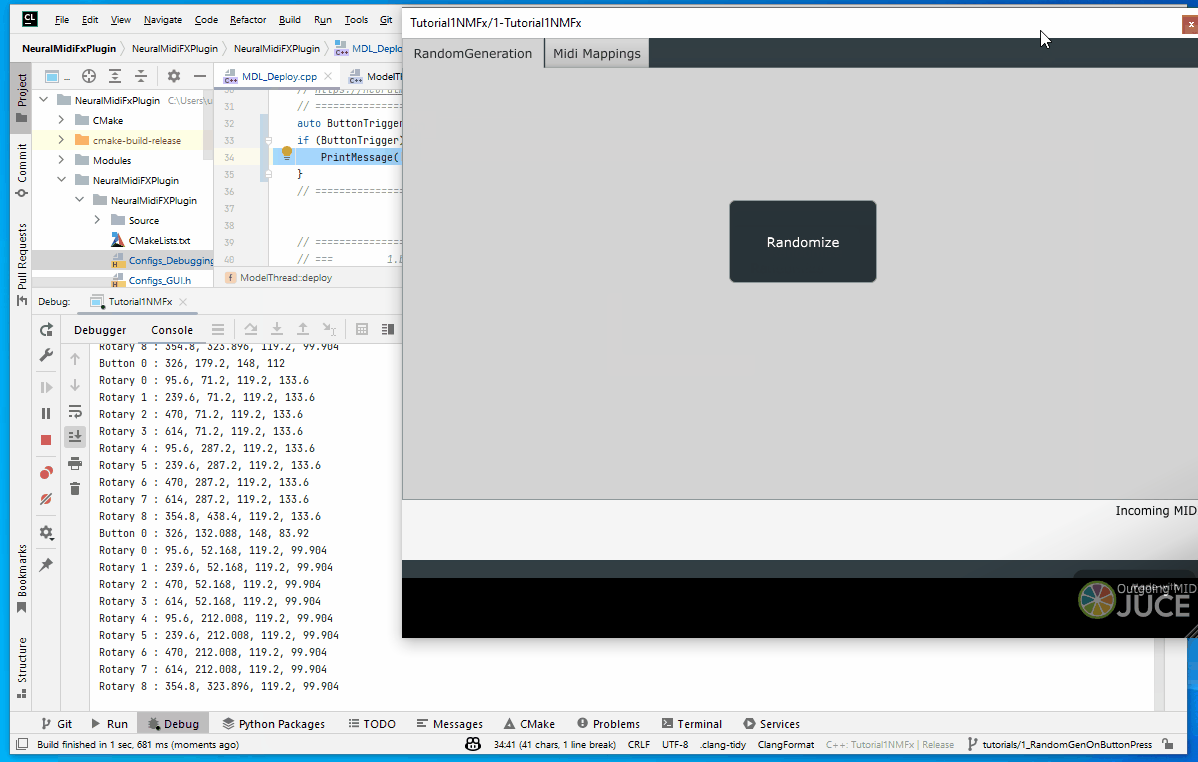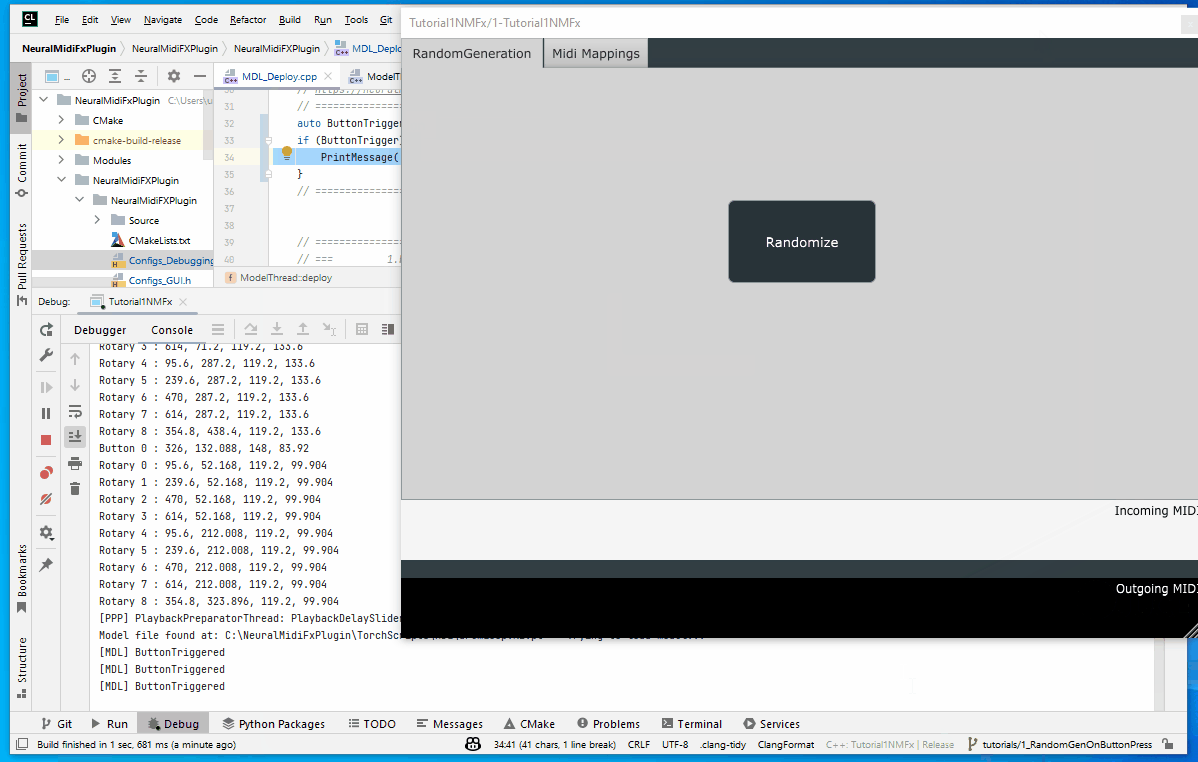
1. Placing a button for random generation
As discussed in the Graphical Interface section of the documentation, to prepare the interface we will need to figure out what UI elements we need as well as how we want to organize them!
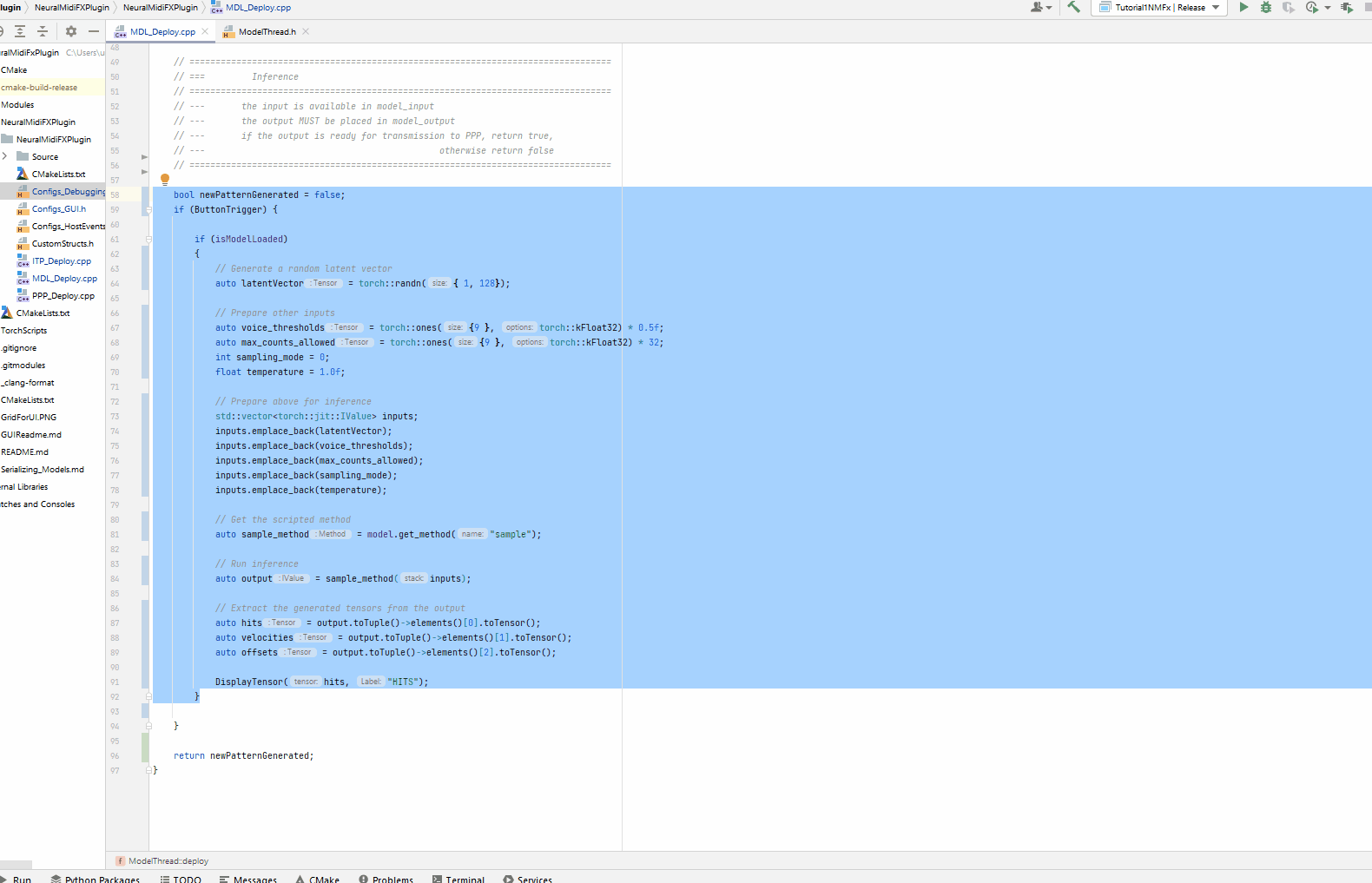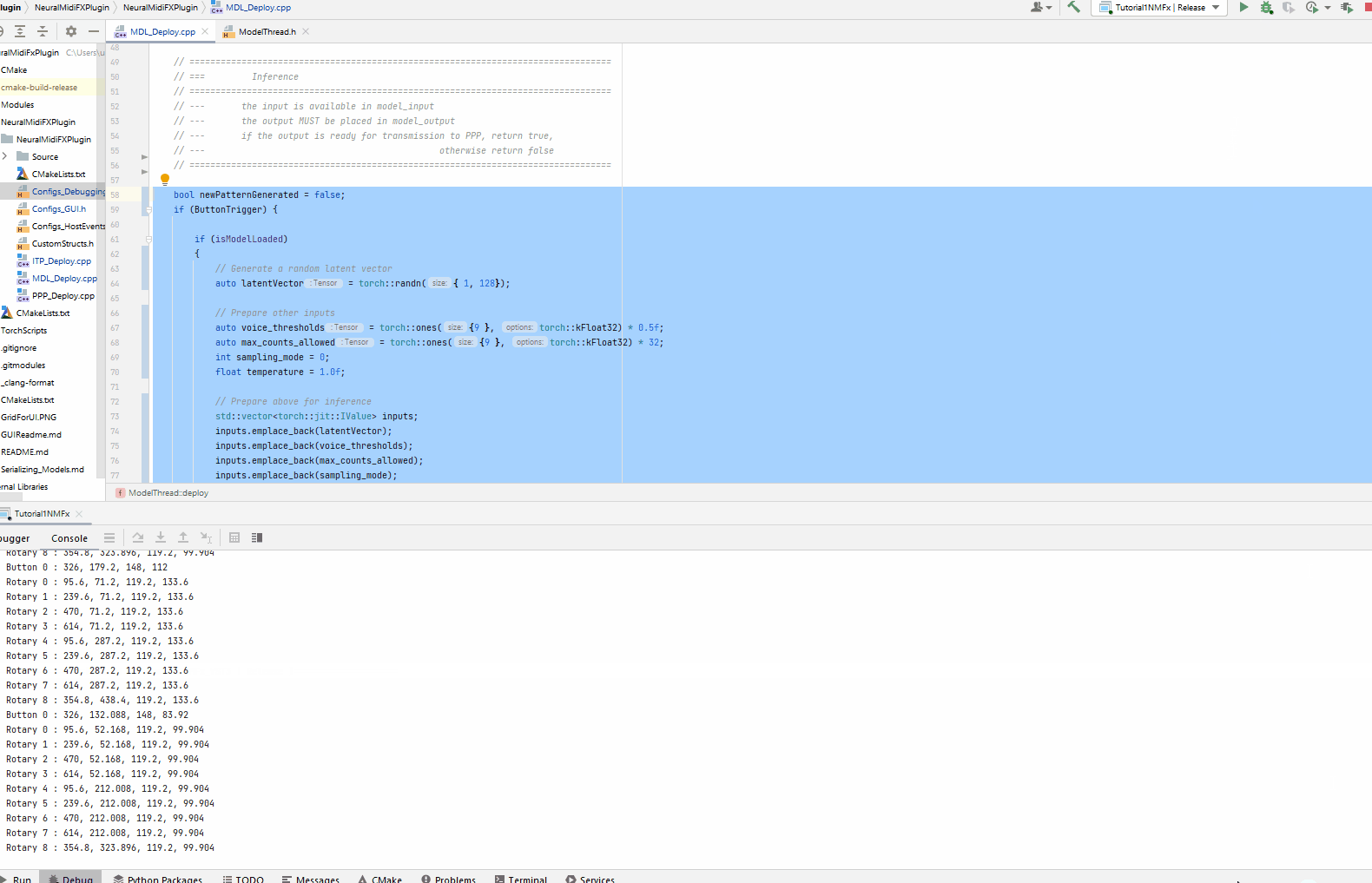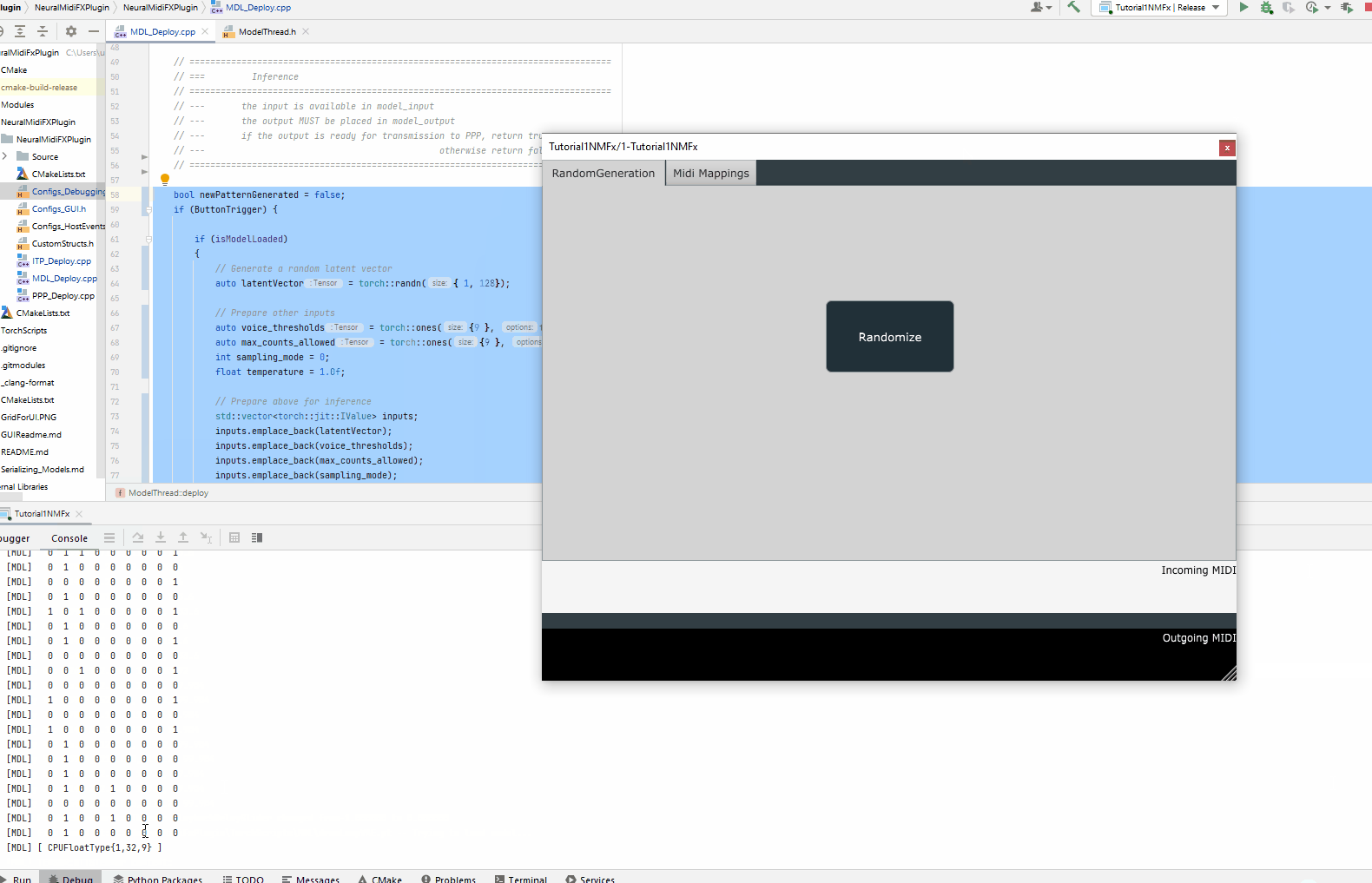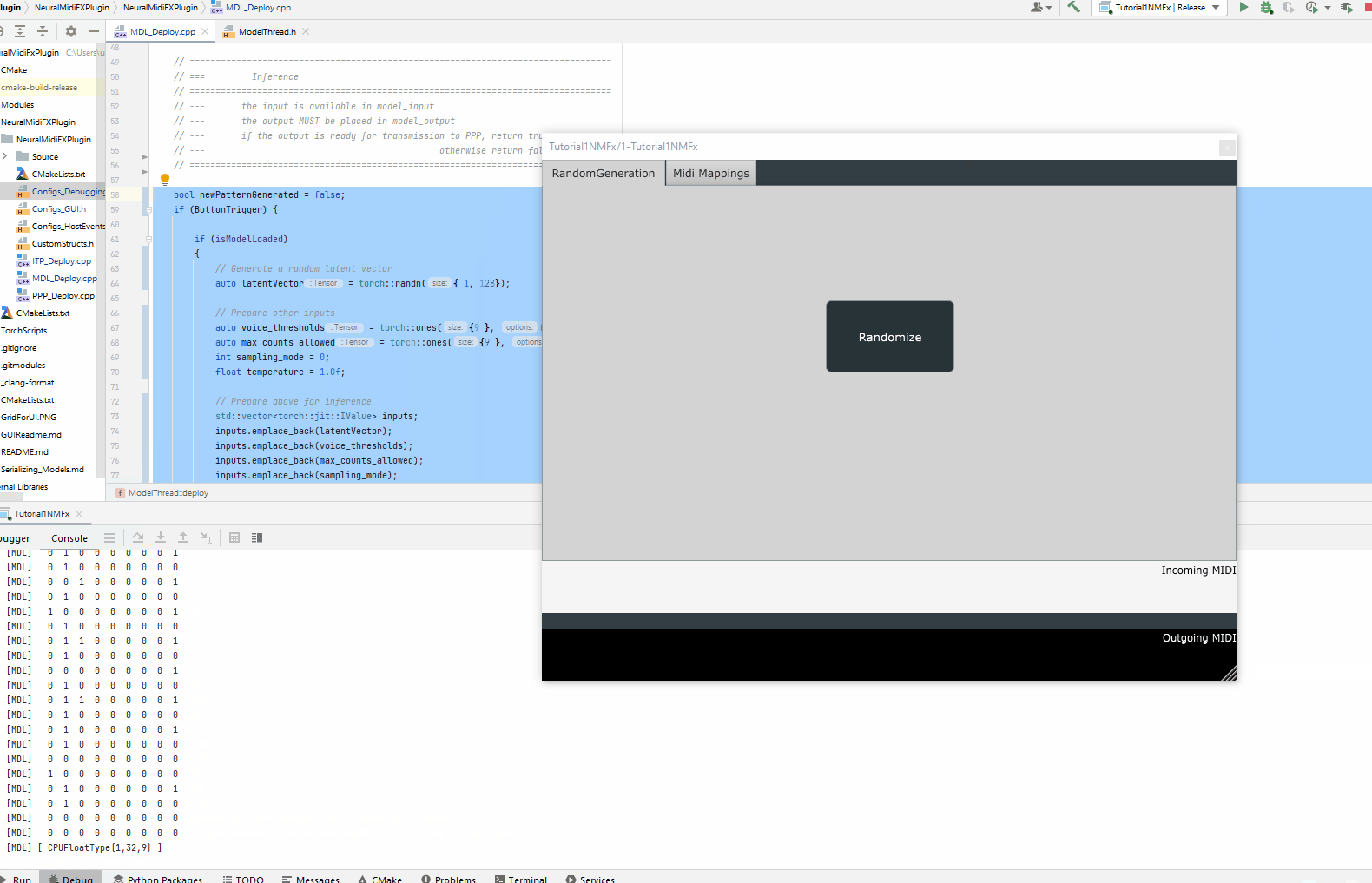
For this demo, all we need is a single button which will trigger the generation of a random pattern. As such, we will modify "UI" field of the settings.json file as follows:
{
"UI": {
"resizable": true,
"maintain_aspect_ratio": true,
"width": 1000,
"height": 800,
"tabList": [
{
"name": "RandomGeneration",
"sliders": [],
"rotaries": [],
"buttons": [{
"label": "Randomize",
"isToggle": false,
"topLeftCorner": "Kh",
"bottomRightCorner": "Pm",
"info": "Press this button to generate a random pattern"
}],
"MidiDisplays": []
}
]
}
}
}
- To be able to easily re-position the button on the Gui, Initially we will setting the
show_gridanddraw_borders_for_componentsto true. once we have positioned the button, we can set these to false to remove the grid and borders.- We don’t need any drag in features for this demo, so we will disable the
MidiInVisualizertab.- We still want to visualize the generations and allow the user to drag them out as midi, so we will enable the
GeneratedContentVisualizertab.

Once rendered, if we are happy with the position of the button, we can set the show_grid and draw_borders_for_components to false.
2. Adding rotaries for per voice midi mappings
As mentioned above, the model has 9 voices, each of which is mapped to a midi note. While we could hard-code these mappings, it would be much more convenient to allow the user to change these mappings from the GUI.
To do this, we will add 9 rotaries to the GUI, each of which will be responsible for changing the midi note of a given voice.
As such, we will add a new tab containing the 9 rotaries to the settings.json file as follows:
{
"name": "Midi Mappings",
"sliders": [],
"rotaries": [
{
"label": "Kick",
"min": 0,
"max": 127,
"default": 36,
"topLeftCorner": "Cc",
"bottomRightCorner": "Gi"
},
{
"label": "Snare",
"min": 0,
"max": 127,
"default": 38,
"topLeftCorner": "Hc",
"bottomRightCorner": "Li"
},
{
"label": "ClosedHat",
"min": 0,
"max": 127,
"default": 42,
"topLeftCorner": "Pc",
"bottomRightCorner": "Ti"
},
{
"label": "OpenHat",
"min": 0,
"max": 127,
"default": 46,
"topLeftCorner": "Uc",
"bottomRightCorner": "Yi"
},
{
"label": "LowTom",
"min": 0,
"max": 127,
"default": 41,
"topLeftCorner": "Cm",
"bottomRightCorner": "Gs"
},
{
"label": "MidTom",
"min": 0,
"max": 127,
"default": 48,
"topLeftCorner": "Hm",
"bottomRightCorner": "Ls"
},
{
"label": "HighTom",
"min": 0,
"max": 127,
"default": 45,
"topLeftCorner": "Pm",
"bottomRightCorner": "Ts"
},
{
"label": "Crash",
"min": 0,
"max": 127,
"default": 49,
"topLeftCorner": "Um",
"bottomRightCorner": "Ys"
},
{
"label": "Ride",
"min": 0,
"max": 127,
"default": 51,
"topLeftCorner": "Lt",
"bottomRightCorner": "Pz"
}
],
"buttons": [],
"MidiDisplays": []
}
Following the same steps as above, we can re-build the plugin and re-open it in the DAW to see the new tab:

All of the parameters added to the GUI are automatically detected by the host and can be automated via the DAW
Deploy() method
Remember that all your implementation will take place in the deploy.h file.
In here we will ensure that the model is loaded, then generate a random latent vector and pass it to the model to generate a new sequence.
Once the new sequence is generated, we will wrap it in a PlaybackSequence and PlaybackPolicy and notify the wrapper to send the sequence to the main thread for playback and visualization.
Model Loading and Random Generation
What we want to do in this method is to:
- Load the model if it has not been loaded already
- Check if the random generation button has been pressed
- On button press, generate a random latent vector
- Call the
sample()method of the model to generate a new sequence
Load the model
The very first step in here is to load the model if it has not been loaded already.
To do this, we will add the following code to the deploy() method:
// =================================================================================
// === LOADING THE MODEL
// =================================================================================
// Try loading the model if it hasn't been loaded yet
if (!isModelLoaded) {
load("drumLoopVAE.pt");
}
Check if random generation button is pressed
To check if the button is pressed, we will be using gui_params which is available to us in the deploy() method.
Here we will check if the button has been clicked and if so, we will print a message to the console
// ...
// =================================================================================
// === ACCESSING GUI PARAMETERS
// Refer to:
// https://neuralmidifx.github.io/docs/V2_1_0/datatypes/GuiParams#accessing-the-ui-parameters
// =================================================================================
auto ButtonTrigger = gui_params.wasButtonClicked("Randomize");
if (ButtonTrigger) {
PrintMessage("ButtonTriggered");
}
// =================================================================================
Generating Random Latent Vector and Preparing other inputs
We will be using a boolean variable called newPatternGenerated to keep track of whether a new pattern has been generated or not. Whenever a new pattern is ready to be sent to next thread, we’ll set this to true.
// ...
if (ButtonTrigger) {
if (isModelLoaded)
{
// Generate a random latent vector
auto latentVector = torch::randn({ 1, 128});
DisplayTensor(latentVector, "latentVector");
}
}
return newPatternGenerated;
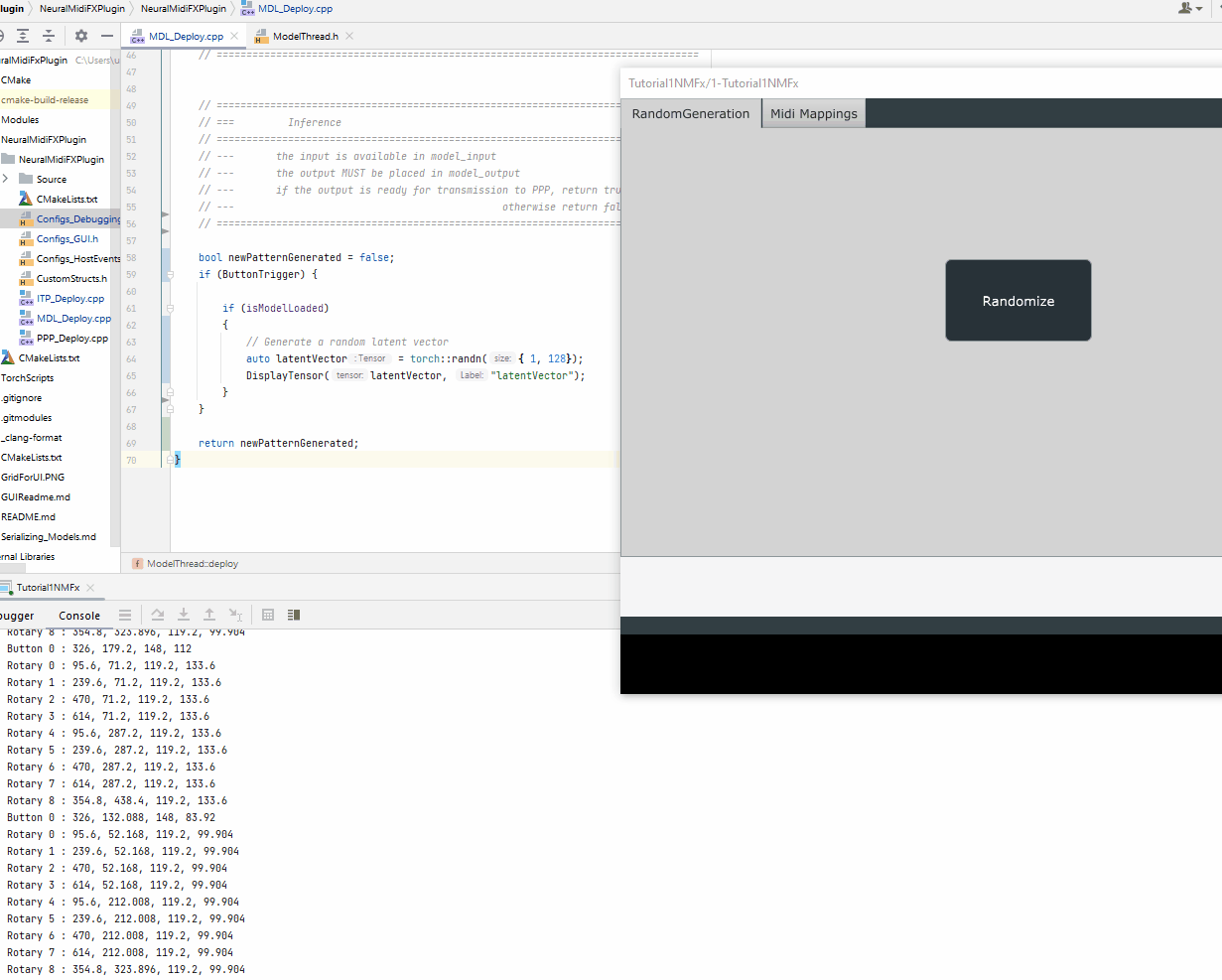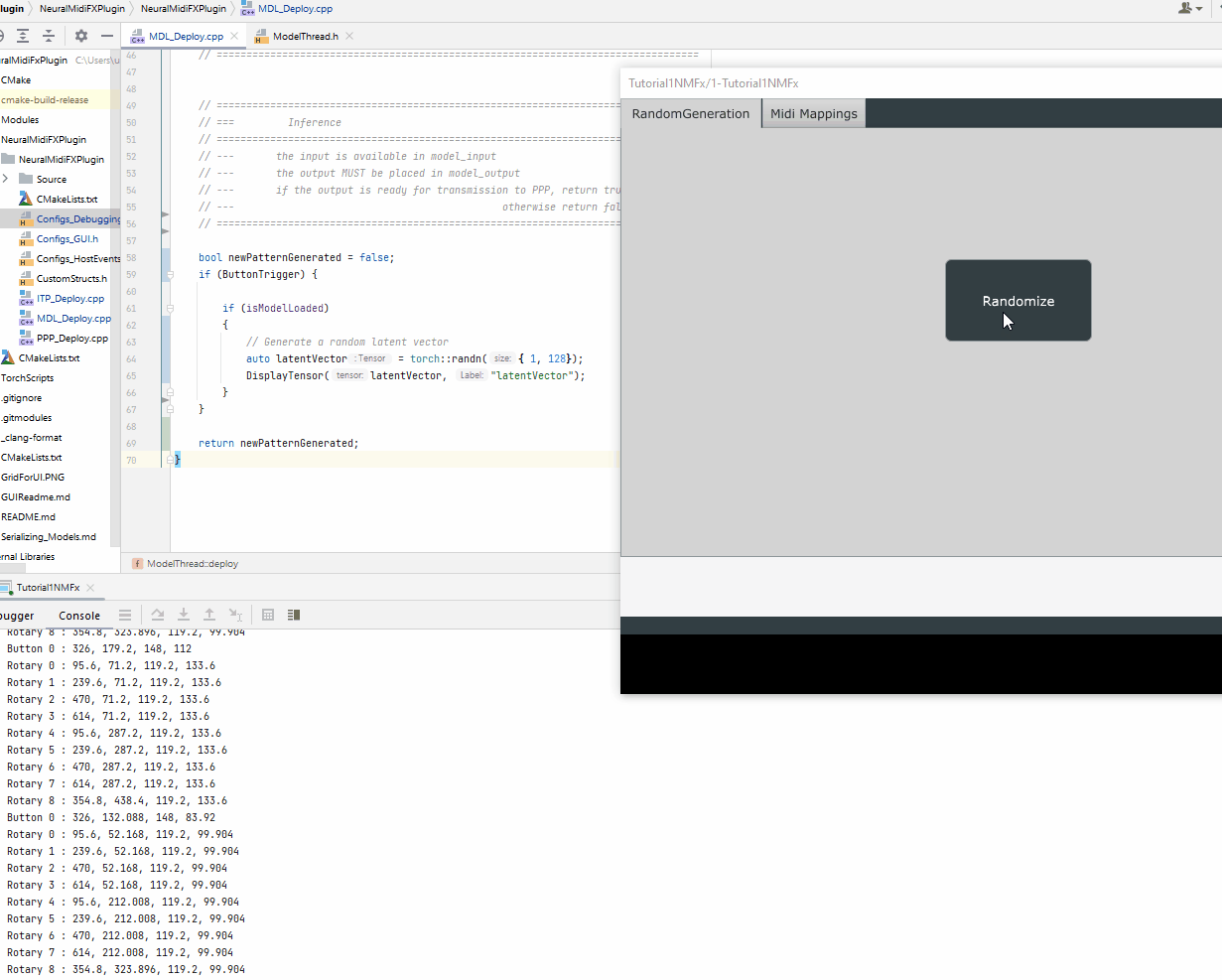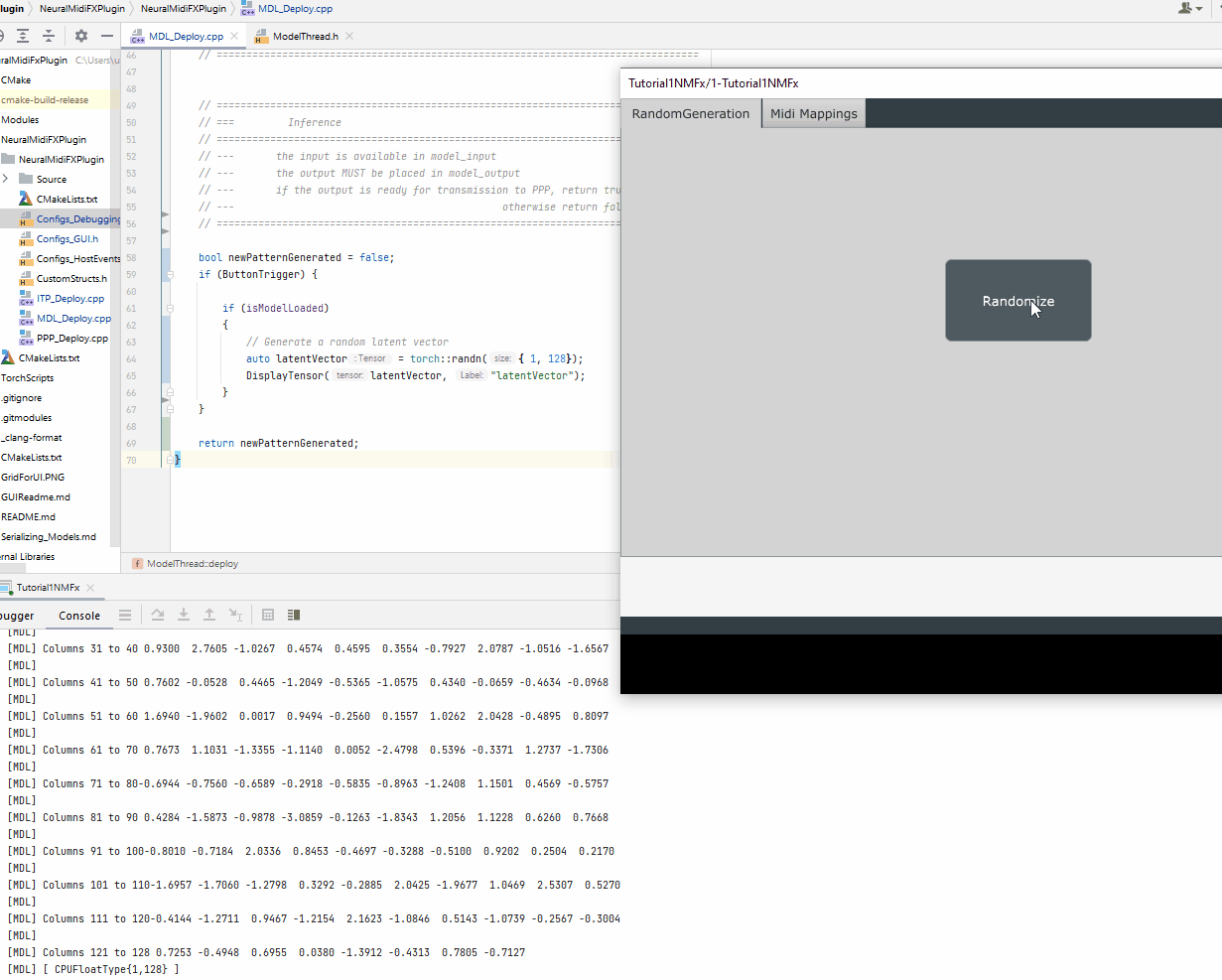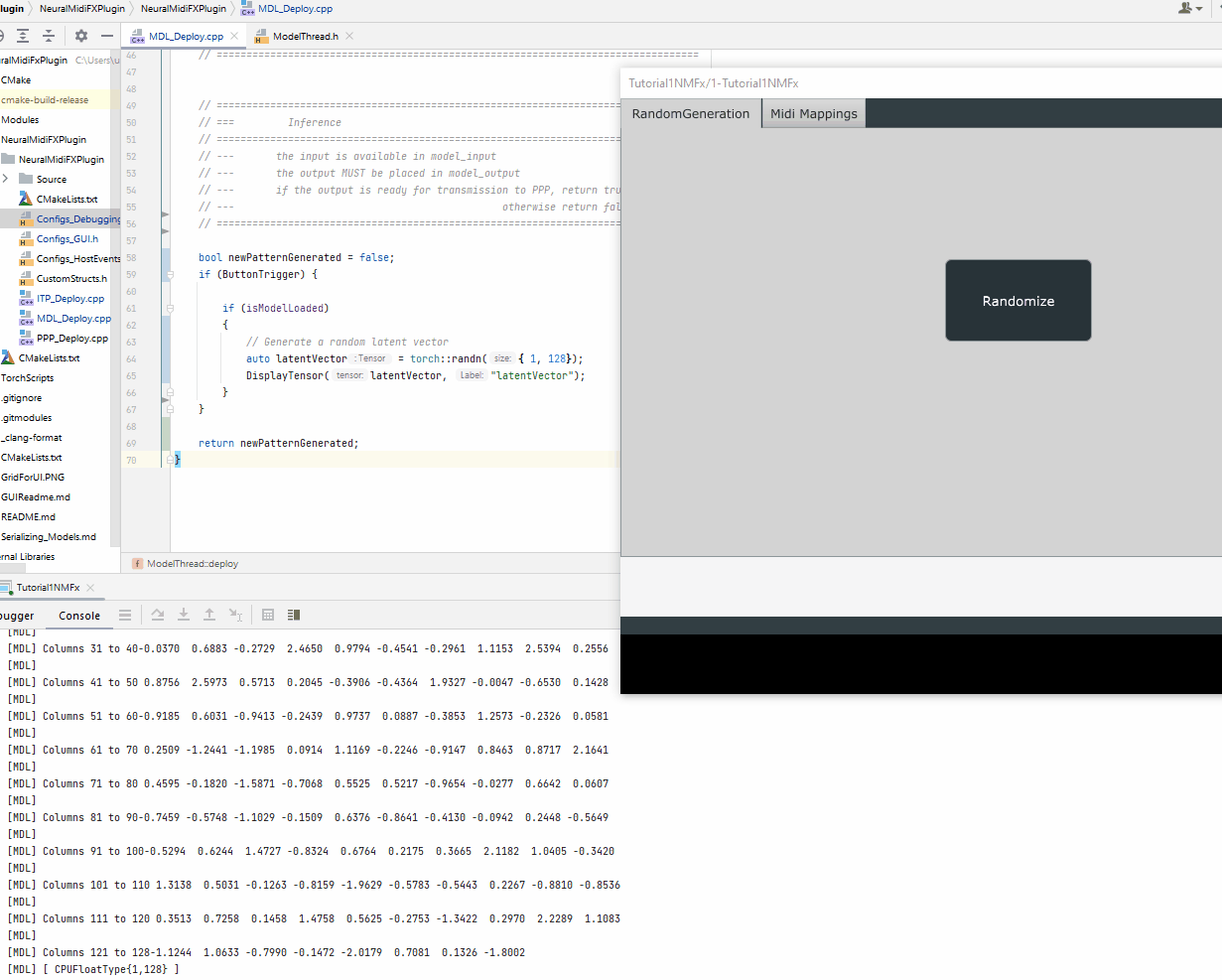
Once the latent vector is generated, we will need to prepare the other inputs to the model based on the interface of the scripted method, sample.
// ...
if (ButtonTrigger) {
if (isModelLoaded)
{
// Generate a random latent vector
auto latentVector = torch::randn({ 1, 128});
// Prepare other inputs
auto voice_thresholds = torch::ones({9 }, torch::kFloat32) * 0.5f;
auto max_counts_allowed = torch::ones({9 }, torch::kFloat32) * 32;
int sampling_mode = 0;
float temperature = 1.0f;
}
}
Inference
Now that all the inputs are ready, we need to add them one by one to a std::vector<torch::jit::IValue>. Then, we need to get the scripted sample method, and subsequently, run inference. Once finished, we can extract the relevant outputs returned from the method
// ...
if (ButtonTrigger) {
if (isModelLoaded)
{
// Generate a random latent vector
auto latentVector = torch::randn({ 1, 128});
// Prepare other inputs
auto voice_thresholds = torch::ones({9 }, torch::kFloat32) * 0.5f;
auto max_counts_allowed = torch::ones({9 }, torch::kFloat32) * 32;
int sampling_mode = 0;
float temperature = 1.0f;
// Prepare above for inference
std::vector<torch::jit::IValue> inputs;
inputs.emplace_back(latentVector);
inputs.emplace_back(voice_thresholds);
inputs.emplace_back(max_counts_allowed);
inputs.emplace_back(sampling_mode);
inputs.emplace_back(temperature);
// Get the scripted method
auto sample_method = model.get_method("sample");
// Run inference
auto output = sample_method(inputs);
// Extract the generated tensors from the output
auto hits = output.toTuple()->elements()[0].toTensor();
auto velocities = output.toTuple()->elements()[1].toTensor();
auto offsets = output.toTuple()->elements()[2].toTensor();
DisplayTensor(hits, "HITS");
}
}
return newPatternGenerated;
Extracting the generated pattern and preparing for playback
Here we want to extract the notes and prepare the pattern for playback. Once the pattern is ready, we will wrap it in a PlaybackSequence and PlaybackPolicy and notify the wrapper to send the sequence to the main thread for playback and visualization.
To learn more about the
PlaybackSequenceandPlaybackPolicyclasses, refer to the Data Types/PlaybackSequence and Data Types/PlaybackPolicy pages respectively.
Extracting the notes and preparing the pattern for playback
First we will create a midi mapping based on the parameters in the second tab of the GUI.
// ...
if (new_model_output_received)
{
// =================================================================================
// === ACCESSING GUI PARAMETERS FOR MIDI MAPPINGS
// Refer to:
// https://neuralmidifx.github.io/docs/V2_1_0/datatypes/GuiParams#accessing-the-ui-parameters
// =================================================================================
std::map<int, int> voiceMap;
voiceMap[0] = int(gui_params.getValueFor("Kick"));
voiceMap[1] = int(gui_params.getValueFor("Snare"));
voiceMap[2] = int(gui_params.getValueFor("ClosedHat"));
voiceMap[3] = int(gui_params.getValueFor("OpenHat"));
voiceMap[4] = int(gui_params.getValueFor("LowTom"));
voiceMap[5] = int(gui_params.getValueFor("MidTom"));
voiceMap[6] = int(gui_params.getValueFor("HighTom"));
voiceMap[7] = int(gui_params.getValueFor("Crash"));
voiceMap[8] = int(gui_params.getValueFor("Ride"));
}
Then, we need to extract the notes from the generated tensors.
This model generates a pattern of 32 steps relative to a 16th note grid. Moreover, the offsets are relative to the gridlines ranging from -0.5 to 0.5. (-0.5 is a 32nd note before the gridline, 0.5 is a 32nd note after the gridline)
bool newPlaybackPolicyShouldBeSent = false;
bool newPlaybackSequenceGeneratedAndShouldBeSent = false;
// ...
// =================================================================================
// === 2. ACCESSING GUI PARAMETERS
// Refer to:
// https://neuralmidifx.github.io/docs/V2_1_0/datatypes/GuiParams
// =================================================================================
std::map<int, int> voiceMap;
voiceMap[0] = int(gui_params.getValueFor("Kick"));
voiceMap[1] = int(gui_params.getValueFor("Snare"));
voiceMap[2] = int(gui_params.getValueFor("ClosedHat"));
voiceMap[3] = int(gui_params.getValueFor("OpenHat"));
voiceMap[4] = int(gui_params.getValueFor("LowTom"));
voiceMap[5] = int(gui_params.getValueFor("MidTom"));
voiceMap[6] = int(gui_params.getValueFor("HighTom"));
voiceMap[7] = int(gui_params.getValueFor("Crash"));
voiceMap[8] = int(gui_params.getValueFor("Ride"));
// =================================================================================
// === 3. Extract Generations into a PlaybackPolicy and PlaybackSequence
// Refer to:
// https://neuralmidifx.github.io/docs/V2_1_0/datatypes/PlaybackPolicy
// https://neuralmidifx.github.io/docs/V2_1_0/datatypes/PlaybackSequence
// =================================================================================
if (!hits.sizes().empty()) // check if any hits are available
{
// clear playback sequence
playbackSequence.clear();
// set the flag to notify new playback sequence is generated
newPlaybackSequenceGeneratedAndShouldBeSent = true;
// iterate through all voices, and time steps
int batch_ix = 0;
for (int step_ix = 0; step_ix < 32; step_ix++)
{
for (int voice_ix = 0; voice_ix < 9; voice_ix++)
{
// check if the voice is active at this time step
if (hits[batch_ix][step_ix][voice_ix].item<float>() > 0.5)
{
auto midi_num = voiceMap[voice_ix];
auto velocity = velocities[batch_ix][step_ix][voice_ix].item<float>();
auto offset = offsets[batch_ix][step_ix][voice_ix].item<float>();
// we are going to convert the onset time to a ratio of quarter notes
auto time = (step_ix + offset) * 0.25f;
playbackSequence.addNoteWithDuration(
0, midi_num, velocity, time, 0.1f);
}
}
}
}
// Specify the playback policy
playbackPolicy.SetPlaybackPolicy_RelativeToAbsoluteZero();
playbackPolicy.SetTimeUnitIsPPQ();
playbackPolicy.SetOverwritePolicy_DeleteAllEventsInPreviousStreamAndUseNewStream(true);
playbackPolicy.ActivateLooping(8);
newPlaybackPolicyShouldBeSent = true;
}
}
// your implementation goes here
return {newPlaybackPolicyShouldBeSent, newPlaybackSequenceGeneratedAndShouldBeSent};
}
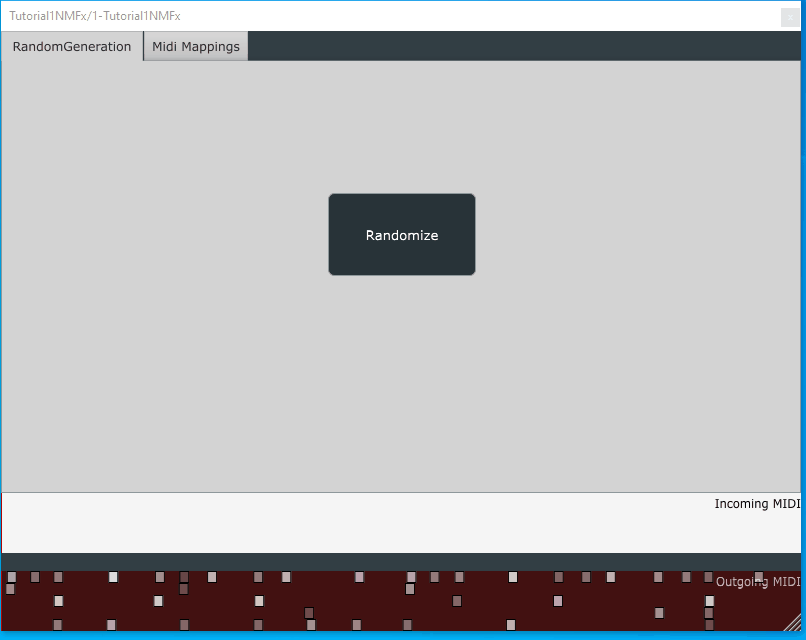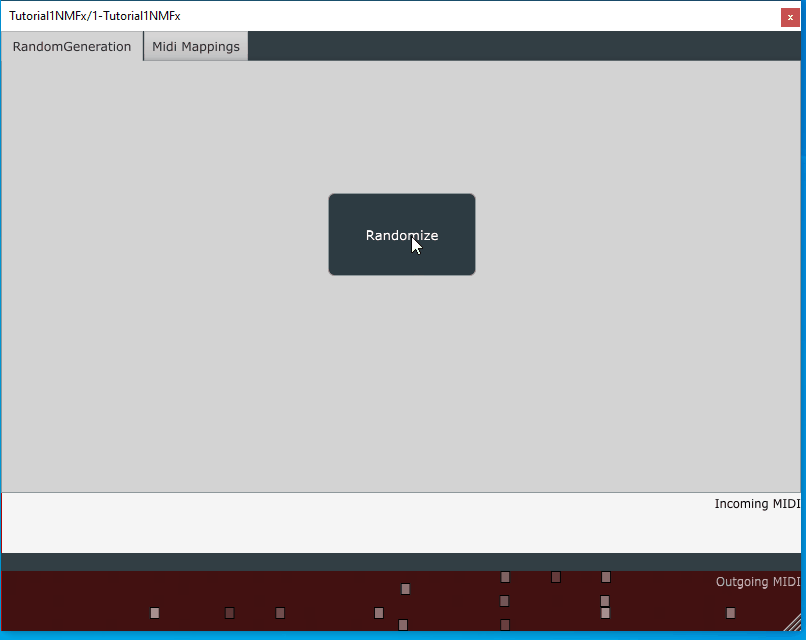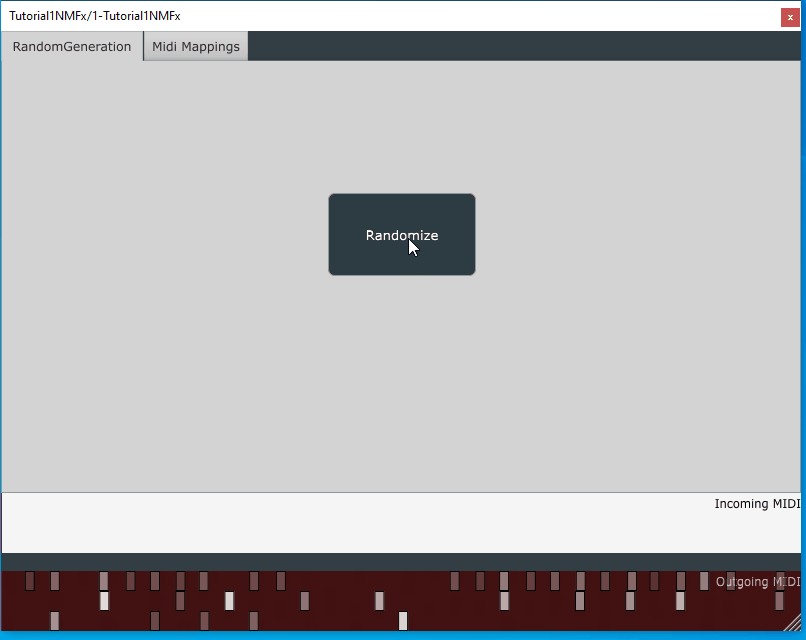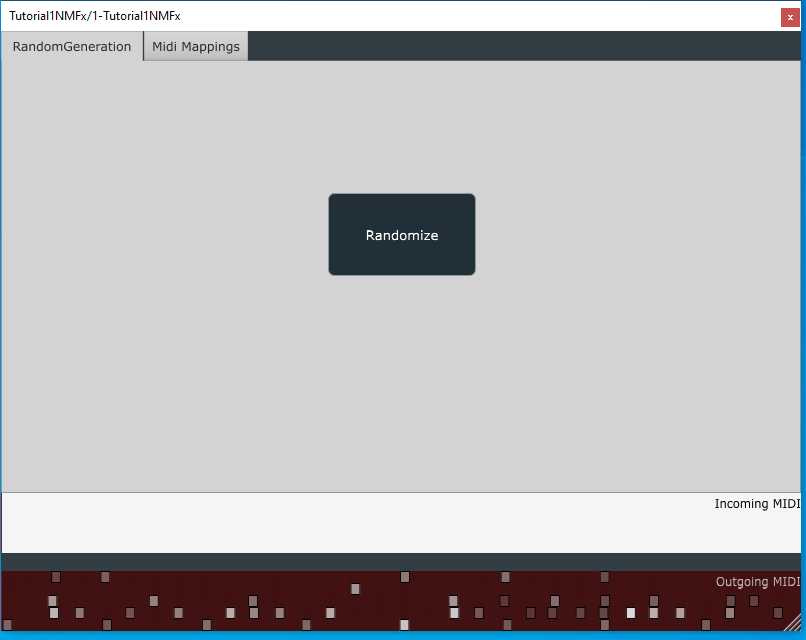
rendered with previous version of the wrapper. The new rendering may look slightly different.
Improving the Implementation [Optional]
Starting in version 2.1.0, the wrapper allows for factorization of the deployment process.
Let’s improve the implementation to improve the re-usability of the code and make it more readable.
Variable Declarations
In the code above, we have a lot of variables that are declared in the deploy() method.
Let’s start by moving the variables that are used in the deploy() method to the private section of the class.
// ...
private:
// add any member variables or methods you need here
torch::Tensor latentVector;
torch::Tensor voice_thresholds = torch::ones({ 9 }, torch::kFloat32) * 0.5f;
torch::Tensor max_counts_allowed = torch::ones({ 9 }, torch::kFloat32) * 32;
int sampling_mode = 0;
float temperature = 1.0f;
std::map<int, int> voiceMap;
torch::Tensor hits;
torch::Tensor velocities;
torch::Tensor offsets;
};
Factorizing the code
Now, let’s factorize the code into smaller methods.
1. updateVoiceMap()
private:
// ...
// checks if any of the voice map parameters have been updated and updates the voice map
// returns true if the voice map has been updated
bool updateVoiceMap() {
bool voiceMapChanged = false;
if (gui_params.wasParamUpdated("Kick")) {
voiceMap[0] = int(gui_params.getValueFor("Kick"));
voiceMapChanged = true;
}
if (gui_params.wasParamUpdated("Snare")) {
voiceMap[1] = int(gui_params.getValueFor("Snare"));
voiceMapChanged = true;
}
if (gui_params.wasParamUpdated("ClosedHat")) {
voiceMap[2] = int(gui_params.getValueFor("ClosedHat"));
voiceMapChanged = true;
}
if (gui_params.wasParamUpdated("OpenHat")) {
voiceMap[3] = int(gui_params.getValueFor("OpenHat"));
voiceMapChanged = true;
}
if (gui_params.wasParamUpdated("LowTom")) {
voiceMap[4] = int(gui_params.getValueFor("LowTom"));
voiceMapChanged = true;
}
if (gui_params.wasParamUpdated("MidTom")) {
voiceMap[5] = int(gui_params.getValueFor("MidTom"));
voiceMapChanged = true;
}
if (gui_params.wasParamUpdated("HighTom")) {
voiceMap[6] = int(gui_params.getValueFor("HighTom"));
voiceMapChanged = true;
}
if (gui_params.wasParamUpdated("Crash")) {
voiceMap[7] = int(gui_params.getValueFor("Crash"));
voiceMapChanged = true;
}
if (gui_params.wasParamUpdated("Ride")) {
voiceMap[8] = int(gui_params.getValueFor("Ride"));
voiceMapChanged = true;
}
return voiceMapChanged;
}
// ...
2. generateRandomPattern()
private:
// ...
// generates a random pattern
void generateRandomPattern() {
// Generate a random latent vector
latentVector = torch::randn({ 1, 128});
// Prepare above for inference
std::vector<torch::jit::IValue> inputs;
inputs.emplace_back(latentVector);
inputs.emplace_back(voice_thresholds);
inputs.emplace_back(max_counts_allowed);
inputs.emplace_back(sampling_mode);
inputs.emplace_back(temperature);
// Get the scripted method
auto sample_method = model.get_method("sample");
// Run inference
auto output = sample_method(inputs);
// Extract the generated tensors from the output
hits = output.toTuple()->elements()[0].toTensor();
velocities = output.toTuple()->elements()[1].toTensor();
offsets = output.toTuple()->elements()[2].toTensor();
}
// ...
3. preparePlaybackSequence()
private:
// ...
// extracts the generated pattern into a PlaybackSequence
void preparePlaybackSequence() {
if (!hits.sizes().empty()) // check if any hits are available
{
// clear playback sequence
playbackSequence.clear();
// iterate through all voices, and time steps
int batch_ix = 0;
for (int step_ix = 0; step_ix < 32; step_ix++)
{
for (int voice_ix = 0; voice_ix < 9; voice_ix++)
{
// check if the voice is active at this time step
if (hits[batch_ix][step_ix][voice_ix].item<float>() > 0.5)
{
auto midi_num = voiceMap[voice_ix];
auto velocity = velocities[batch_ix][step_ix][voice_ix].item<float>();
auto offset = offsets[batch_ix][step_ix][voice_ix].item<float>();
// we are going to convert the onset time to a ratio of quarter notes
auto time = (step_ix + offset) * 0.25f;
playbackSequence.addNoteWithDuration(
0, midi_num, velocity, time, 0.1f);
}
}
}
}
}
// ...
4. preparePlaybackPolicy()
private:
// ...
// prepares the playback policy
void preparePlaybackPolicy() {
// Specify the playback policy
playbackPolicy.SetPlaybackPolicy_RelativeToAbsoluteZero();
playbackPolicy.SetTimeUnitIsPPQ();
playbackPolicy.SetOverwritePolicy_DeleteAllEventsInPreviousStreamAndUseNewStream(true);
playbackPolicy.ActivateLooping(8);
}
// ...
5. update the deploy() method
public:
// ...
// this method runs on a per-event basis.
// the majority of the deployment will be done here!
std::pair<bool, bool> deploy (
std::optional<MidiFileEvent> & new_midi_event_dragdrop,
std::optional<EventFromHost> & new_event_from_host,
bool gui_params_changed_since_last_call,
bool new_preset_loaded_since_last_call,
bool new_midi_file_dropped_on_visualizers,
bool new_audio_file_dropped_on_visualizers) override {
// Try loading the model if it hasn't been loaded yet
if (!isModelLoaded) {
load("drumLoopVAE.pt");
}
// Check if voice map should be updated
bool voiceMapChanged = false;
if (gui_params_changed_since_last_call) {
voiceMapChanged = updateVoiceMap();
}
// generate a new pattern on button request
bool generatedNewPattern = false;
if (gui_params.wasButtonClicked("Randomize")) {
if (isModelLoaded)
{
// Generate a random pattern
generateRandomPattern();
generatedNewPattern = true;
}
}
// if the voice map has changed, or a new pattern has been generated,
// prepare the playback sequence
if ((voiceMapChanged || generatedNewPattern) && isModelLoaded) {
preparePlaybackSequence();
preparePlaybackPolicy();
return {true, true};
}
// your implementation goes here
return {false, false};
}
// ...