Overview & Architecture
Explain what this section is about
Table of contents
- Purpose and Overview of the Wrapper
- Your Responsibilities vs. the Wrapper’s Responsibilities
- How the Wrapper Facilitates VST3 Plugin Development
- Architecture
Purpose and Overview of the Wrapper
This guide is designed to assist researchers in deploying generative neural network models of symbolic music as VST3 plugins. Utilizing this wrapper, you can easily integrate your research models into the VST3 framework without needing expertise in VST development.
Target Audience: The primary audience for this guide includes researchers and practitioners working in the field of generative symbolic music, particularly those focusing on neural network-based models.
Your Responsibilities vs. the Wrapper’s Responsibilities
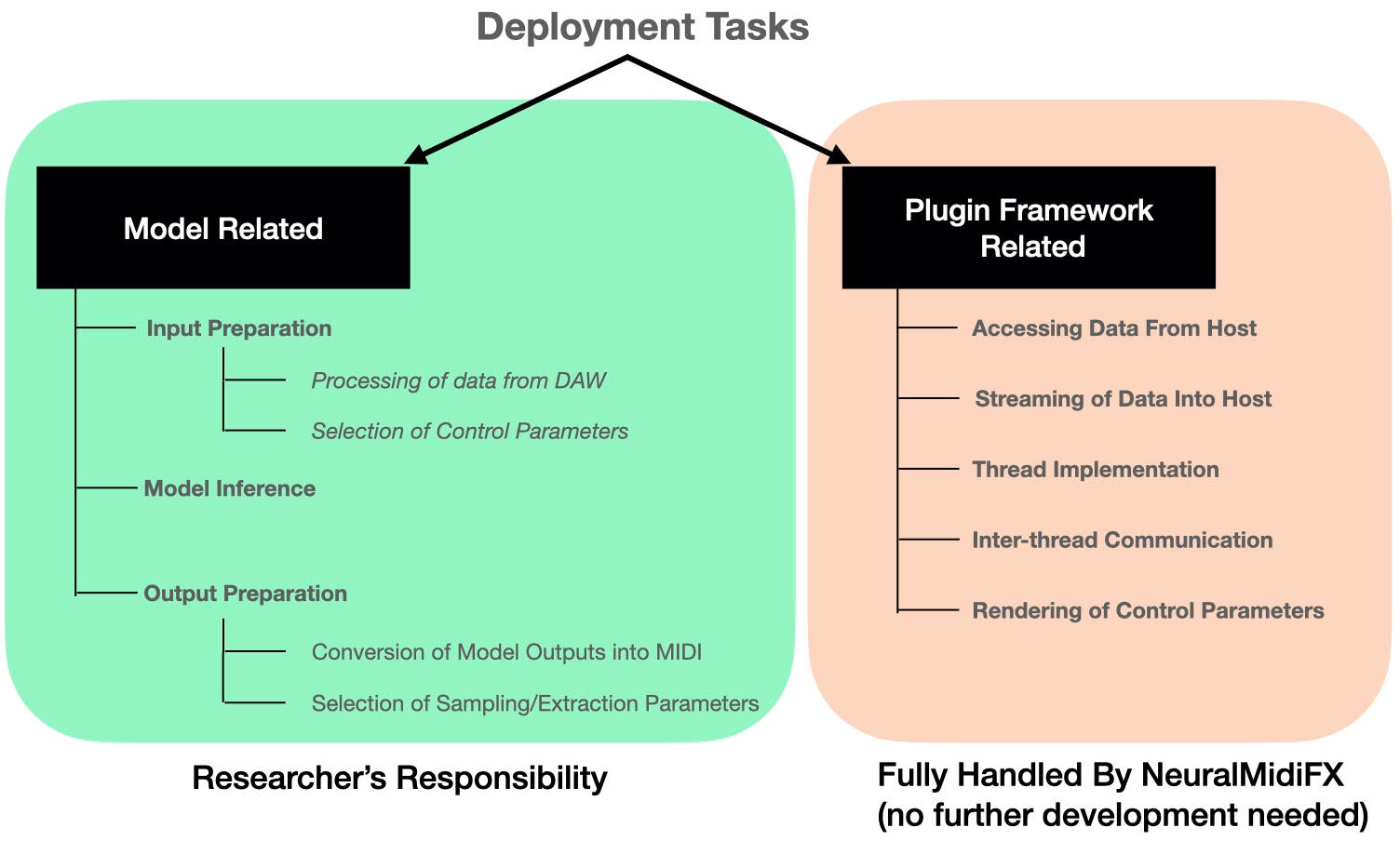
The wrapper was to be developed for researchers that (1) do not have any prior experience with plugin development and (2) require support for a variety of generative tasks. To accommodate this second point, we concluded that any process that may be model specific should be the responsibility of the user of the template, while any other aspect of the development should be fully streamlined by NeuralMidiFx. In this context, a number of tasks are clearly the responsibility of the wrapper as they are model independent: handling the reception of incoming information from the host, streaming of generated content, creating globally accessible parameters, and rendering a graphical interface.
The proposed wrapper, NeuralMidiFx, fully automates the deployment processes that are specific to plugin development frameworks. However, tasks related to the model are not fully automated as they are highly dependent on the specific task at hand. Nonetheless, knowing that the stages involved in the inference process can be distinctly divided into three separate procedures (Input Preparation, Model Inference, and Output Preparation/Post-Processing), NeuralMidiFx provides dedicated threads for each of these procedures, with specific access points made available to the researcher. This allows for greater control and customization of the model-related tasks, while still providing an easy and streamlined process for plugin development.
How the Wrapper Facilitates VST3 Plugin Development
With this wrapper, you can:
- Integrate serialized PyTorch neural network models with ease.
- Customize the user interface for control and interaction.
- Implement/optimize real-time processing and playback.
Architecture
The wrapper is designed to be as flexible as possible while still providing a streamlined process for plugin development. Specifically, the intention behind the architecture is to streamline a number of technically challenging aspects of the deployment process, such as (1) multi-threaded design, (2) thread-safe data communication, (3) parameter control, and (4) interface design.
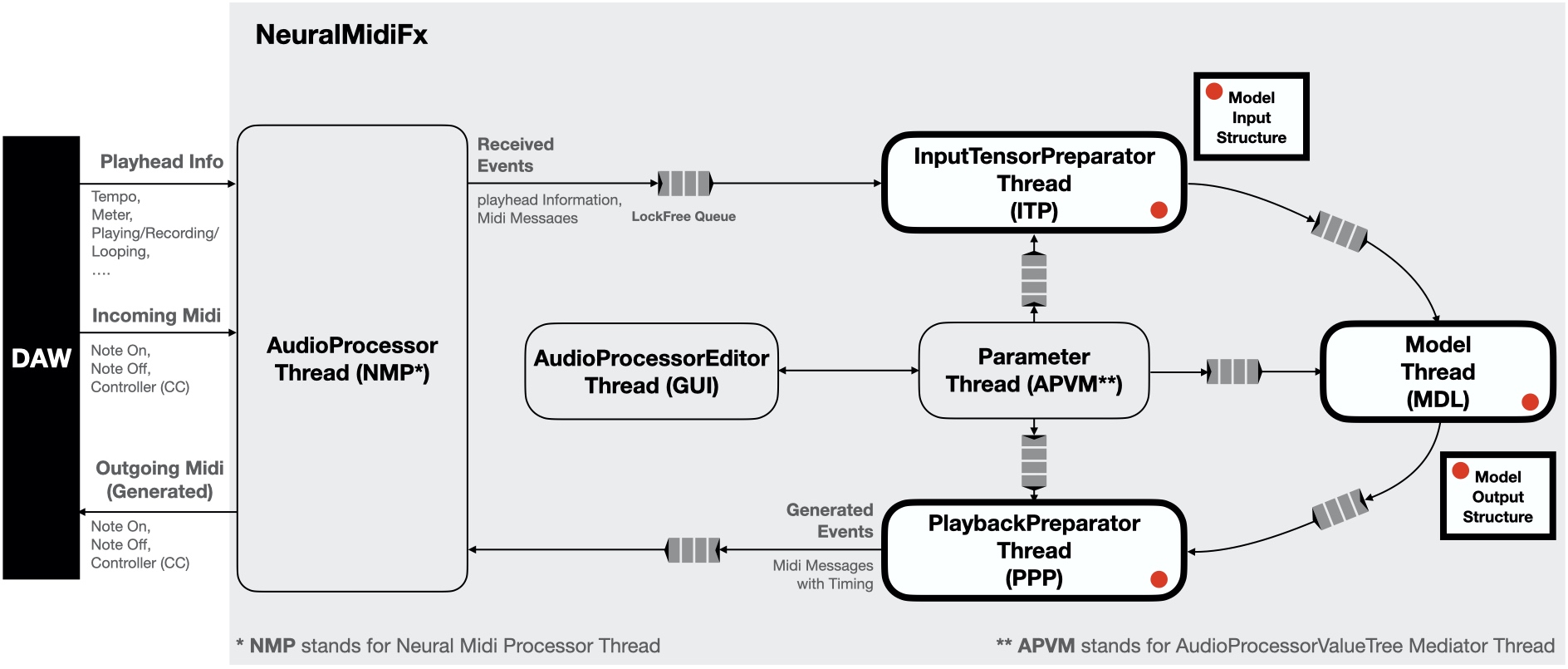
Host-Wrapper Communication
The wrapper fully handles the communication between the host and the plugin. This includes the reception of incoming MIDI messages, the streaming of generated MIDI messages, syncronization with the host, and the creation of globally accessible parameters. As such, the user of the wrapper does not need to worry about any of these aspects of the development process. All you need to know is that all necessary information received the host is provided to you in an easy-to-use format, and that you can send MIDI messages to the host with ease as well.
Plugin Parameter and Interface Rendering
The wrapper allows you to create globally accessible parameters that can be controlled by the user of the plugin. These parameters are associated with a graphical component (slider, button, etc.) that is rendered in the plugin’s interface. The wrapper handles the rendering of the interface and the communication between the interface and the parameters. Moreover, all these parameters are automatable, meaning that the user can record their changes in the host and play them back later.
See Plugin Parameters and Interface Rendering
Input Preparation for Model Inference
A dedicated thread (InputTensorPreparator - ITP) is provided for the input preparation stage of the inference process. In this thread, any information necessary for input preparation/tokenization is provided to you sequentially to process. This includes the incoming MIDI messages (whether played in real-time or dragged in manually via MIDI files), the playhead information of the host, and all the specified parameters of the plugin.
See DeploymentThreads/Input Tensor Preparator Thread (ITP)
Model Inference
A dedicated thread (Model - MDL) is provided for the model inference stage of the inference process. In this thread, you can perform the inference process using the input information provided by the ITP thread.
See DeploymentThreads/Model Thread (MDL)
Output Preparation/Post-Processing
A dedicated thread (PlaybackPreparator - PPP) is provided for the output preparation stage of the inference process. In here you can extract the output information from the model and pass it on to the wrapper for playback.
See DeploymentThreads/Playback Preparator Thread (PPP)
Passing Information Between Threads
The wrapper provides thread-safe communication channels dedicated for ITP-to-MDL, MDL-to-PPP communication. You can modify the structure of the data passed between these threads to suit your needs, however, the wrapper provides the thread safe communication channels in which the data is passed. This means that you do not need to worry about how to safely exchange information between threads but rather focus on what information you need to exchange.
See DeploymentThreads/ITP/Model Input Structure
See DeploymentThreads/MDL/PPP Output Structure