Table of contents
- Model Description
- Plugin Name and Description
- GUI and Parameters
- Deploy() methods
Tutorial 1 - Random Generation on Button Press
In this tutorial, we will learn how to unconditionaly generate a random drum loop on a button press.
the source code for this tutorial is available in the tutorials branch of the repository.
Model Description
The model we will be using in this exercise is a VariationalAutoEncoder (VAE) trained on the Groove Midi Dataset.
The model has been trained on 2-bar drum loops in 4/4 time signature.
The model has already been serialized and is available at TorchScripts/Models/drumLoopVAE.pt
Input/Output Description
The input and output of the model are both 3 stacked tensors of shape (32, 9) where 32 is the number of 16th notes in a 2-bar segment and 9 is the number of drum instruments. The three stacked tensors are as follows:
hits: A binary tensor indicating whether or not a drum instrument is hit at a given time stepvelocities: A tensor indicating the velocity of the drum instrument at a given time stepoffsets: A tensor indicating the offset of the drum instrument at a given time step
Methods available
The model has multiple methods available, some of which we will be using in this tutorial. The python definitions of these models are as follows:
1. encode
This method encodes a given input pattern into a latent vector. The method returns a number of parameters, however the third parameter is the latent vector we are interested in.
We will not be using this method until Tutorial 3. A more detailed description of this method will be provided here
2. sample
This method decodes a given latent vector into an output tensor and returns a hits, velocities, and offsets tensors describing the output pattern.
The input to this method requires a number of additional parameters, however, for the purposes of this tutorial, we will not be discussing them.
def sample(self, latent_z, voice_thresholds, voice_max_count_allowed, sampling_mode: int = 0,
temperature: float = 1.0):
"""Converts the latent vector into hit, vel, offset values
:param latent_z: (Tensor) [N x latent_dim]
:param voice_thresholds: [N x 9] (floatTensor) Thresholds for hit prediction
:param voice_max_count_allowed: [N x 9] (floatTensor) Maximum number of hits to allow for each voice
:param sampling_mode: (int) 0 for top-k sampling,
1 for bernoulli sampling
:param temperature: (float) temperature for sampling
Returns:
h, v, o, _h
"""
Midi Mappings
The 9 voices of the model are as follows:
| Index | Instrument | Midi Note |
|---|---|---|
| 0 | Kick | 36 |
| 1 | Snare | 38 |
| 2 | Closed HiHat | 42 |
| 3 | Open HiHat | 46 |
| 4 | Low Tom | 41 |
| 5 | Mid Tom | 47 |
| 6 | High Tom | 50 |
| 7 | Crash Cymbal | 49 |
| 8 | Ride Cymbal | 51 |
Plugin Name and Description
As mentioned here, we need to specify the name of the plugin as well as some descriptions for it.
To do this, we will modify the NeuralMidiFXPlugin/NeuralMidiFXPlugin/CMakeLists.txt file as follows:
project(Tutorial1NMFx VERSION 0.0.1)
set (BaseTargetName Tutorial1NMFx)
....
juce_add_plugin("${BaseTargetName}"
COMPANY_NAME "AIMCTutorials"
...
PLUGIN_CODE AZCK # a unique 4 character code for your plugin
...
PRODUCT_NAME "Tutorial1NMFx") # Replace with your plugin title
Once you re-build the cmake project, and re-build the plugin, you should see the name of the plugin change in the DAW:
Now we are ready to move on to the next step.
GUI and Parameters
1. Placing a button for random generation
As discussed in the Graphical Interface section of the documentation, to prepare the interface we will need to figure out what UI elements we need as well as how we want to organize them!
For this tutorial, all we need is a single button which will trigger the generation of a random pattern. As such, we will modify the Configs_GUI.h file as follows:
namespace Tabs {
const bool show_grid = true;
const bool draw_borders_for_components = true;
const std::vector<tab_tuple> tabList{
tab_tuple
{
"RandomGeneration", // use any name you want for the tab
slider_list
{
},
rotary_list
{
},
button_list
{
button_tuple{"Randomize", false, "Kh", "Pm"}
}
}
};
},
namespace MidiInVisualizer {
const bool enable = false;
// ....
},
namespace GeneratedContentVisualizer
{
const bool enable = true;
const bool allowToDragOutAsMidi = true;
}
- To be able to easily re-position the button on the Gui, Initially we will setting the
show_gridanddraw_borders_for_componentsto true. once we have positioned the button, we can set these to false to remove the grid and borders.- We don’t need any drag in features for this tutorial, so we will disable the
MidiInVisualizertab.- We still want to visualize the generations and allow the user to drag them out as midi, so we will enable the
GeneratedContentVisualizertab.

Once rendered, if we are happy with the position of the button, we can set the show_grid and draw_borders_for_components to false.
2. Adding rotaries for per voice midi mappings
As mentioned above, the model has 9 voices, each of which is mapped to a midi note. While we could hard-code these mappings, it would be much more convenient to allow the user to change these mappings from the GUI.
To do this, we will add 9 rotaries to the GUI, each of which will be responsible for changing the midi note of a given voice.
As such, we will add a new tab containing the 9 rotaries to the Configs_GUI.h file as follows:
tab_tuple
{
"Midi Mappings",
slider_list
{
},
rotary_list
{
rotary_tuple{"Kick", 0, 127, 36, "Cc", "Gi"},
rotary_tuple{"Snare", 0, 127, 38, "Hc", "Li"},
rotary_tuple{"ClosedHat", 0, 127, 42, "Pc", "Ti"},
rotary_tuple{"OpenHat", 0, 127, 46, "Uc", "Yi"},
rotary_tuple{"LowTom", 0, 127, 41, "Cm", "Gs"},
rotary_tuple{"MidTom", 0, 127, 48, "Hm", "Ls"},
rotary_tuple{"HighTom", 0, 127, 45, "Pm", "Ts"},
rotary_tuple{"Crash", 0, 127, 49, "Um", "Ys"},
rotary_tuple{"Ride", 0, 127, 51, "Lt", "Pz"},
},
button_list
{
}
}
Following the same steps as above, we can re-build the plugin and re-open it in the DAW to see the new tab:
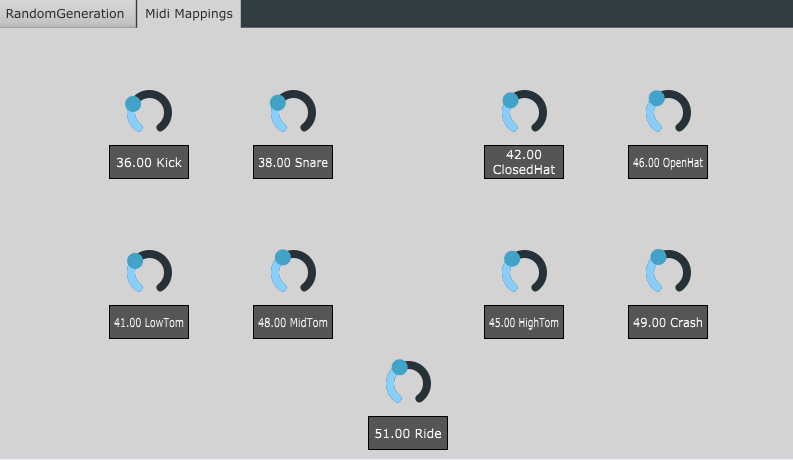
All of the parameters added to the GUI are automatically detected by the host and can be automated via the DAW
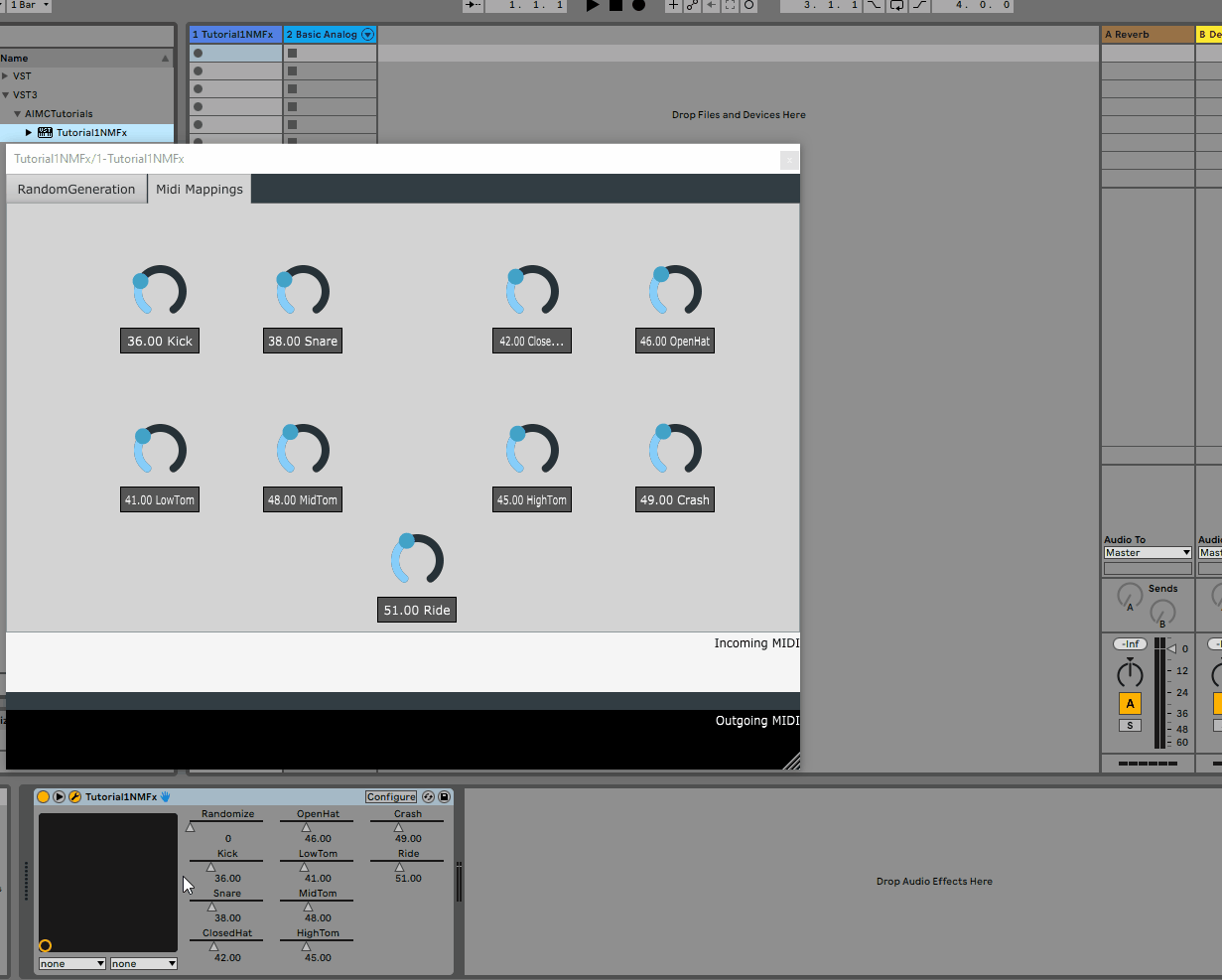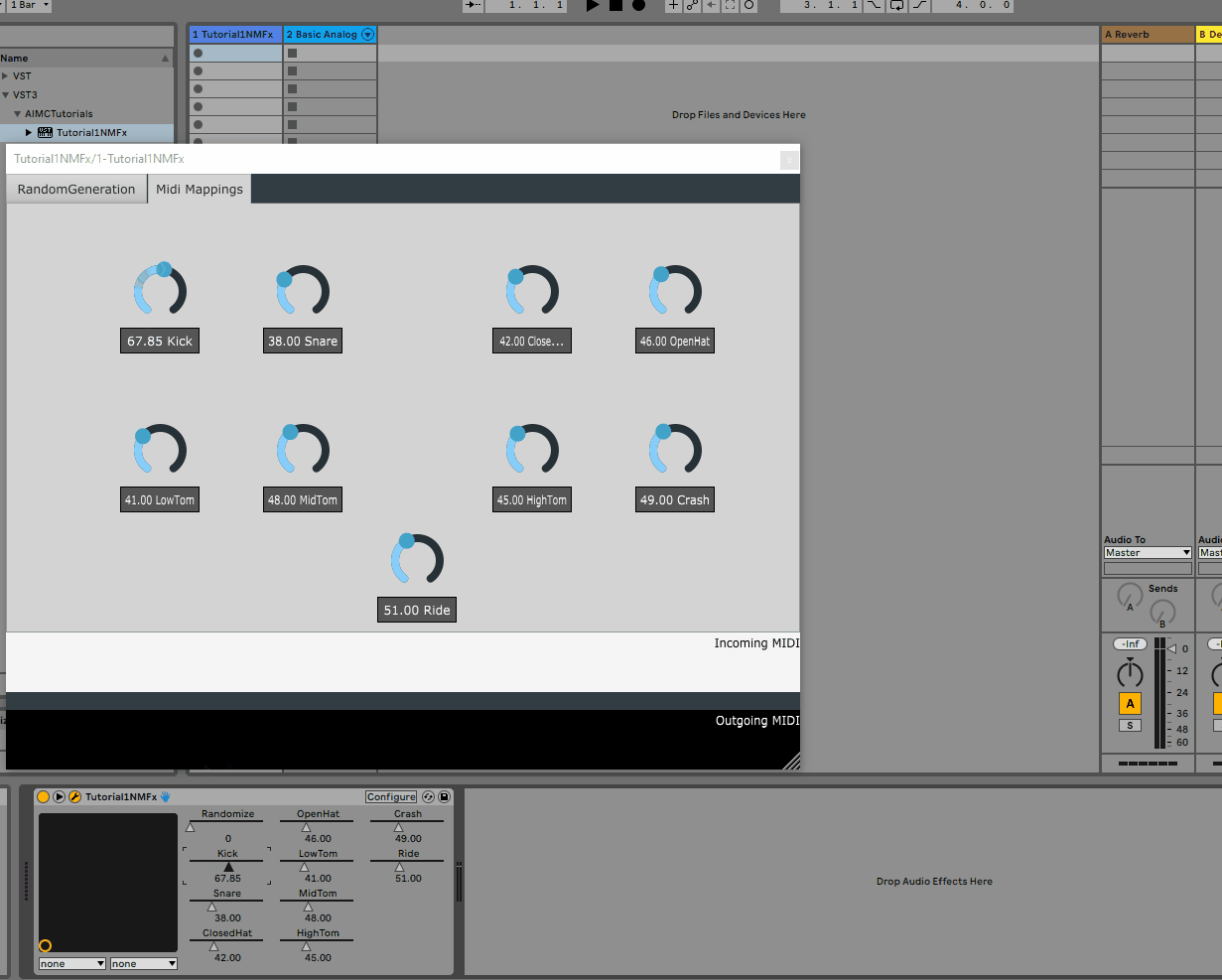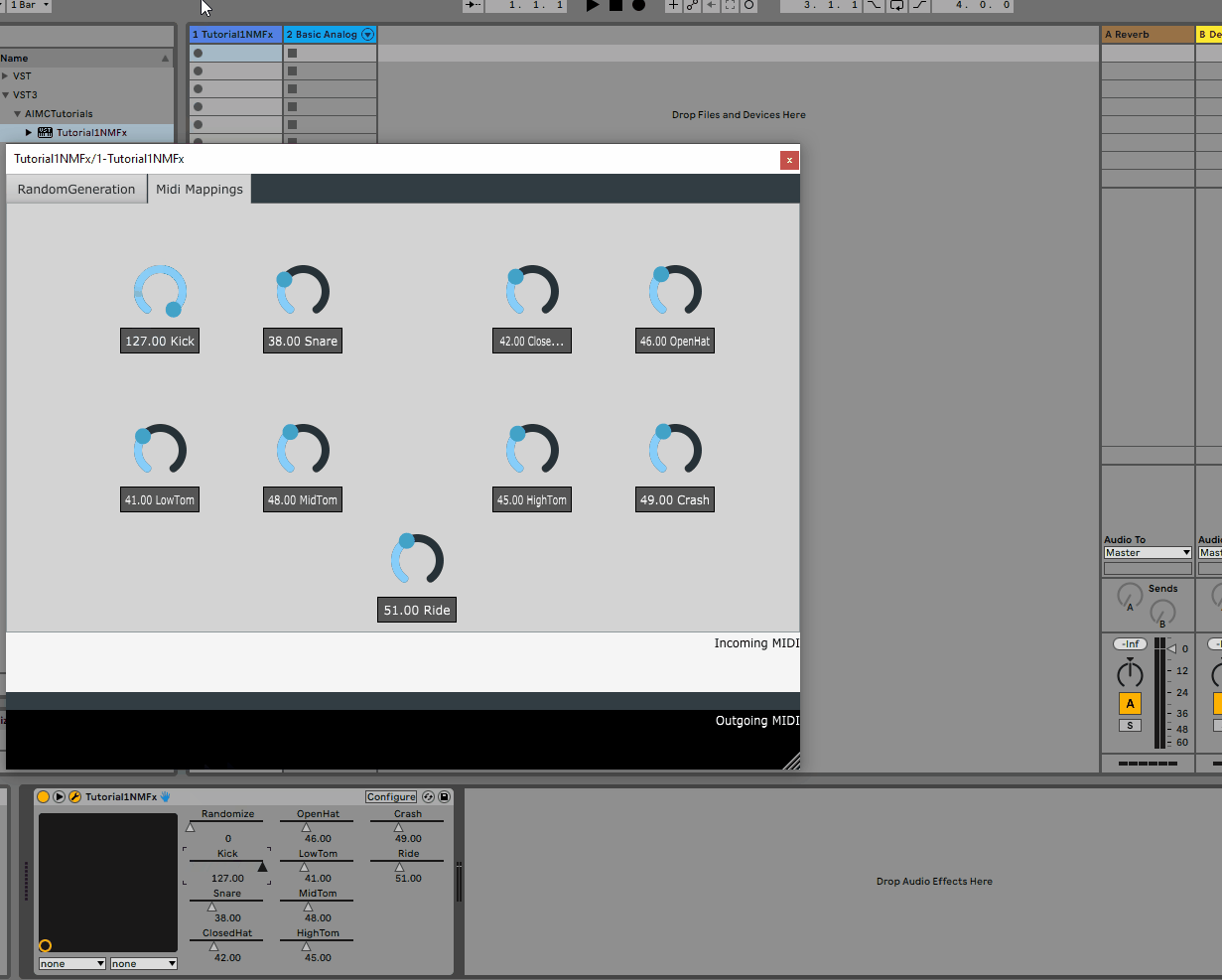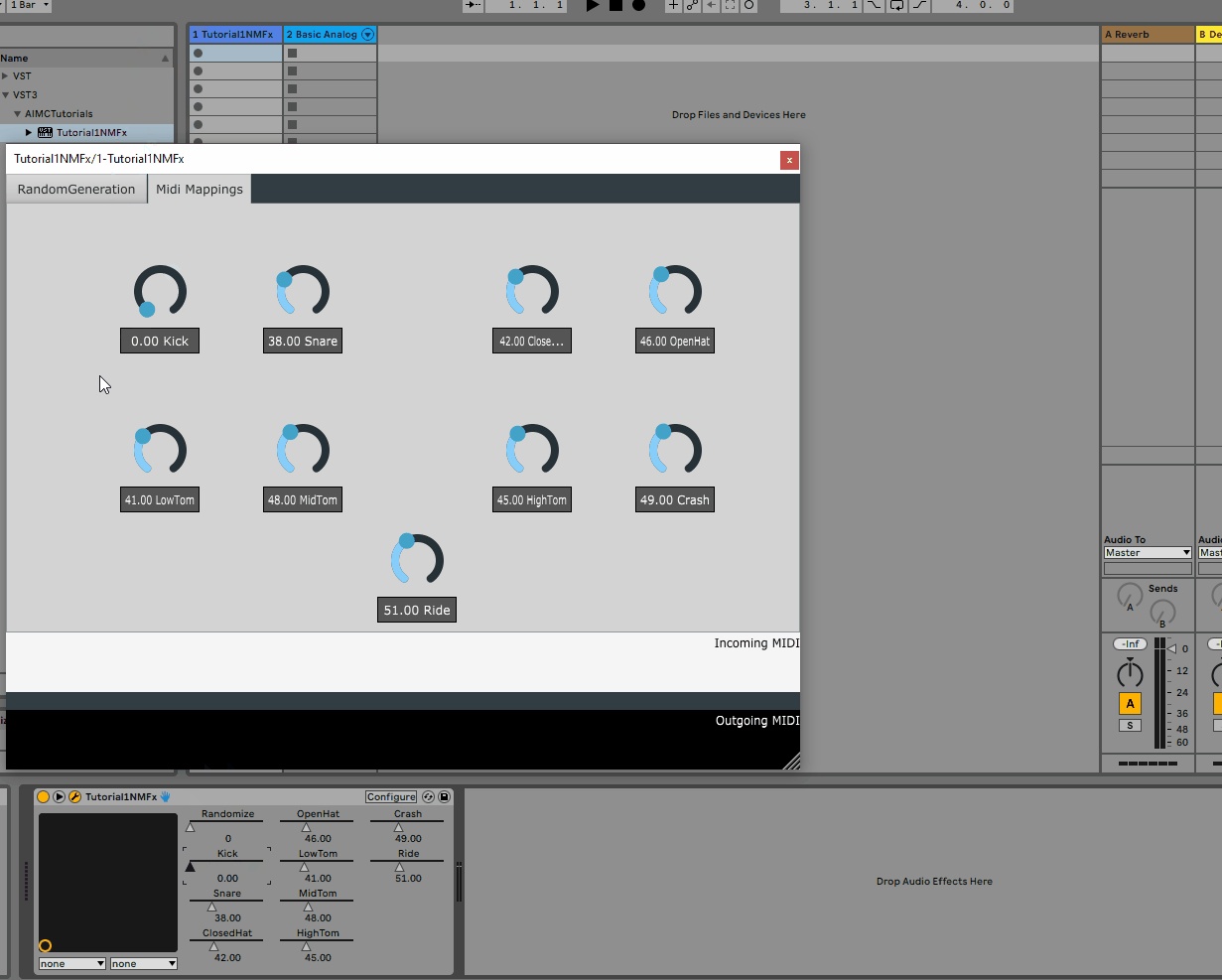
Deploy() methods
Remember that there are three Deploy() methods that you need to implement:
InputTensorPreparatorThread::deploy()in ITP_Deploy.cppModelThread::deploy()in Model_Deploy.cppPlaybackPreparatorThread::deploy(}in PPP_Deploy.cpp
In this tutorial, given that we are not using any input midi, we will only need to implement the ModelThread::deploy() and PlaybackPreparatorThread::deploy(} methods.
ModelThread::deploy()
What we want to do in this method is to:
- Load the model if it has not been loaded already
- Check if the random generation button has been pressed
- On button press, generate a random latent vector
- Call the
sample()method of the model to generate a new sequence - Wrap the generated pattern in
model_outputand pass it to thePPPthread
Load the model
The very first step in here is to load the model if it has not been loaded already.
To do this, we will add the following code to the ModelThread::deploy() method:
// ModelThread::deploy() method in MDL_Deploy.cpp
// =================================================================================
// === 0. LOADING THE MODEL
// =================================================================================
// Try loading the model if it hasn't been loaded yet
if (!isModelLoaded) {
load("drumLoopVAE.pt");
}
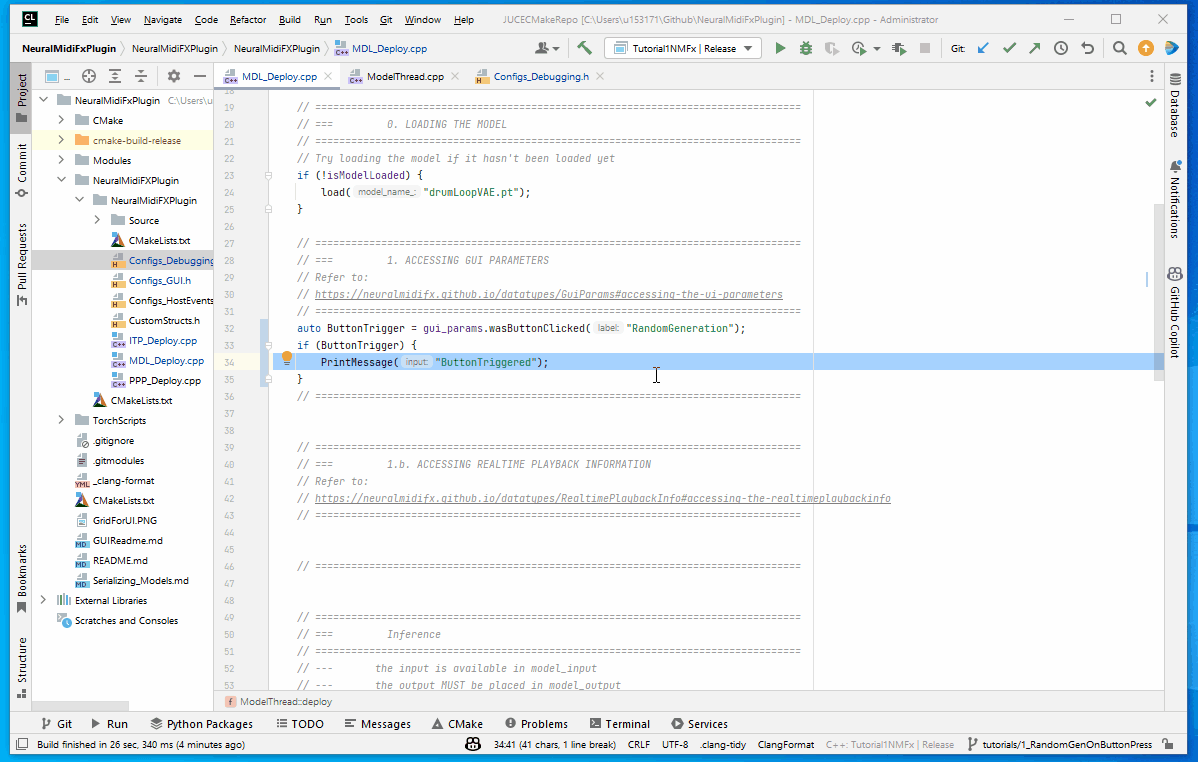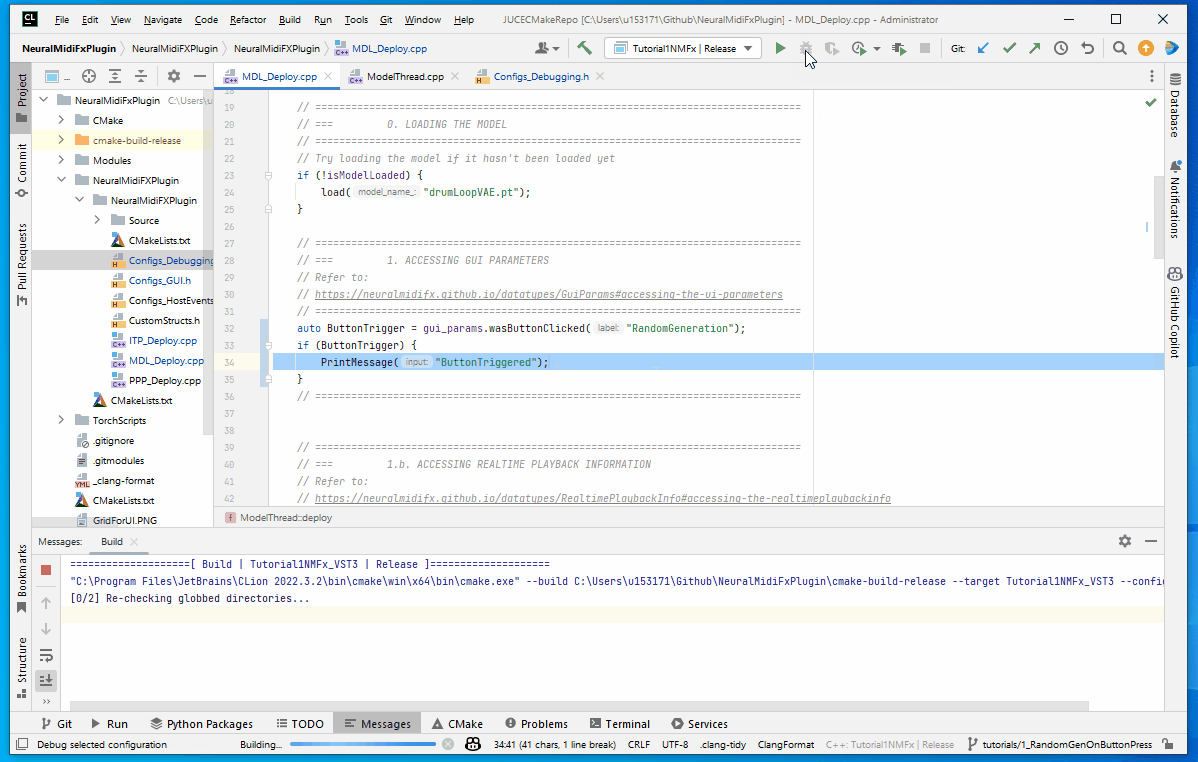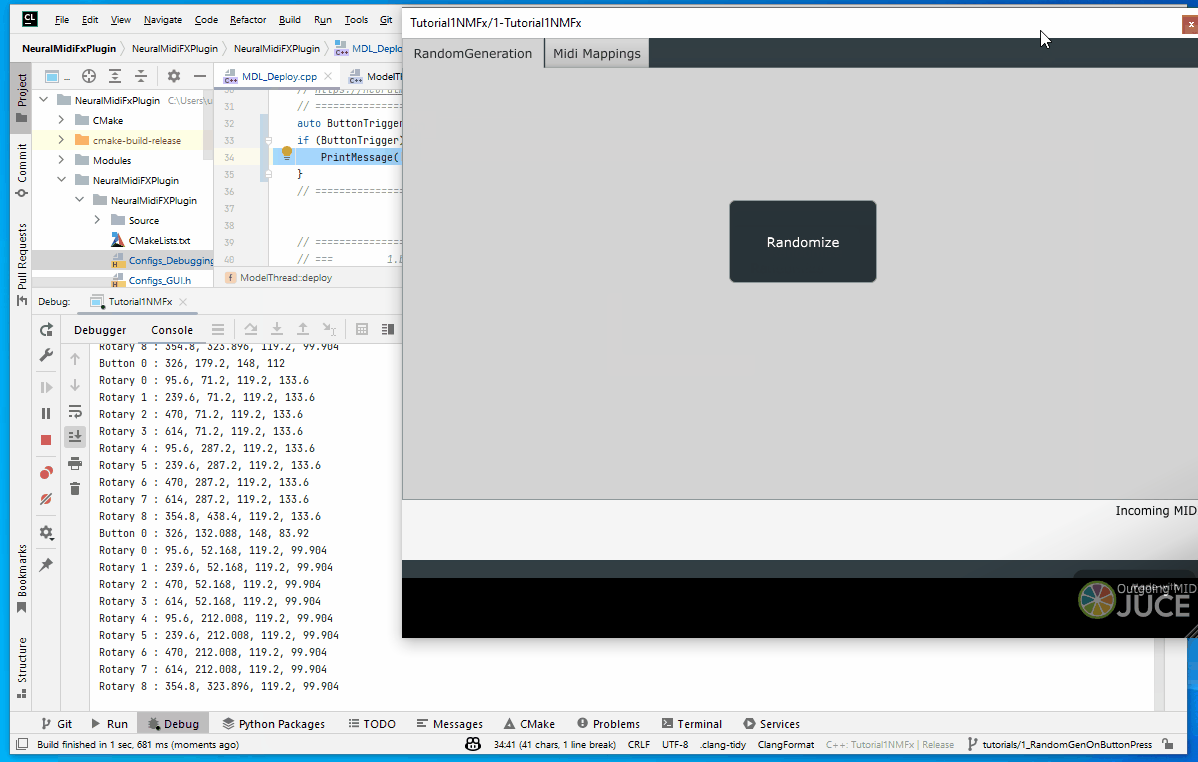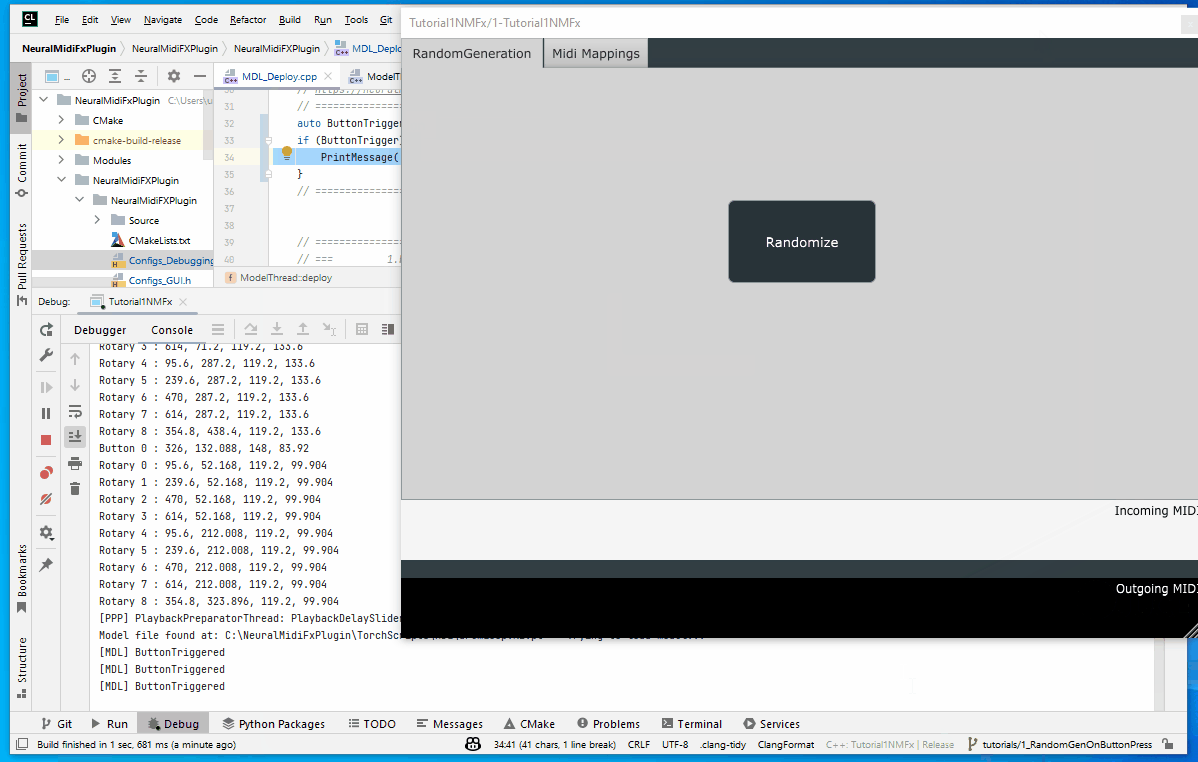
Check if random generation button is pressed
To check if the button is pressed, we will be using gui_params which is a member of the ModelThread class.
Here we will check if the button has been clicked and if so, we will print a message to the console
// ModelThread::deploy() method in MDL_Deploy.cpp
// ...
// =================================================================================
// === 1. ACCESSING GUI PARAMETERS
// Refer to:
// https://neuralmidifx.github.io/docs/v1_0_0/datatypes/GuiParams#accessing-the-ui-parameters
// =================================================================================
auto ButtonTrigger = gui_params.wasButtonClicked("Randomize");
if (ButtonTrigger) {
PrintMessage("ButtonTriggered");
}
// =================================================================================
Generating Random Latent Vector and Preparing other inputs
We will be using a boolean variable called newPatternGenerated to keep track of whether a new pattern has been generated or not. Whenever a new pattern is ready to be sent to next thread, we’ll set this to true.
// ModelThread::deploy() method in MDL_Deploy.cpp
// ...
bool newPatternGenerated = false;
if (ButtonTrigger) {
if (isModelLoaded)
{
// Generate a random latent vector
auto latentVector = torch::randn({ 1, 128});
DisplayTensor(latentVector, "latentVector");
}
}
return newPatternGenerated;
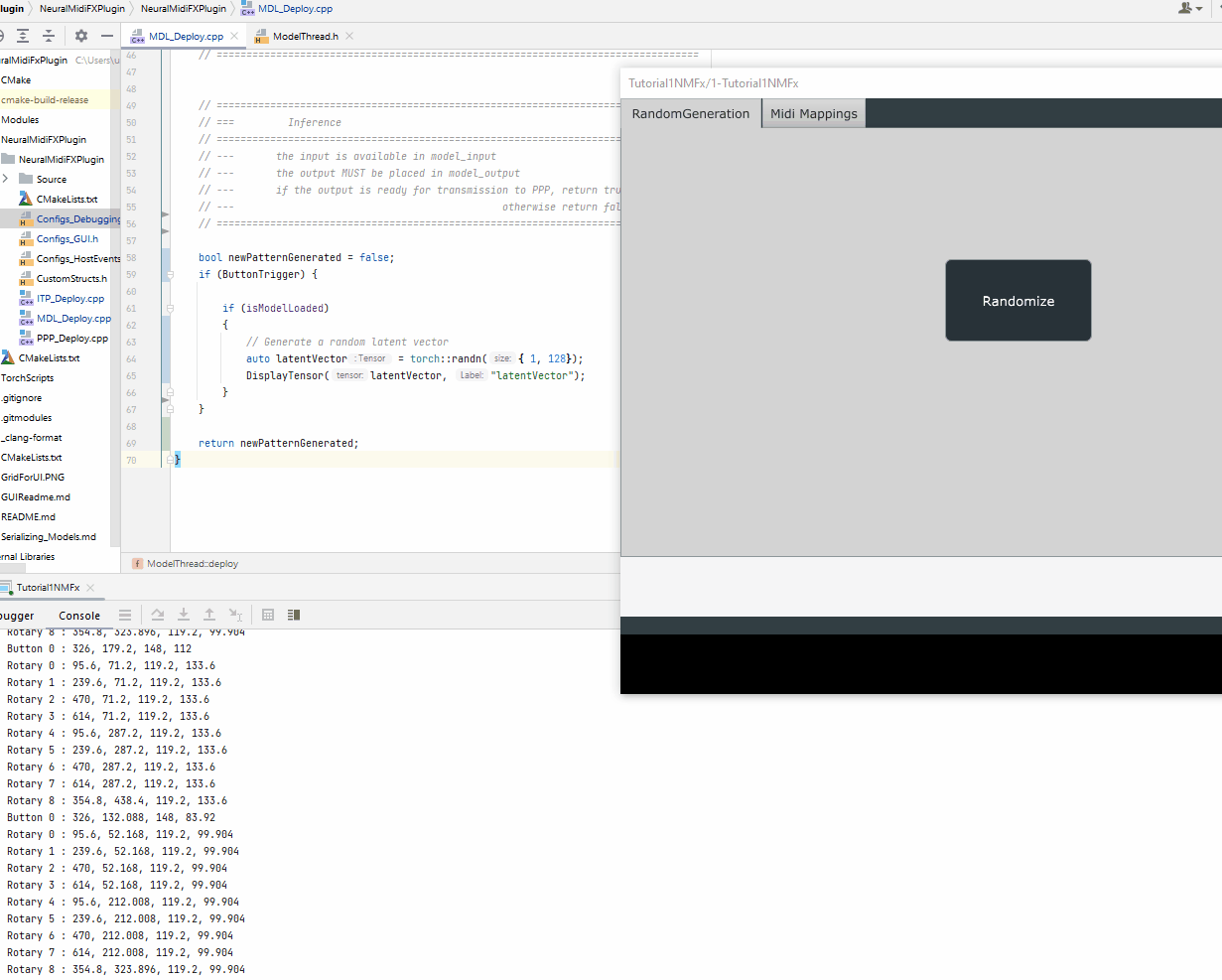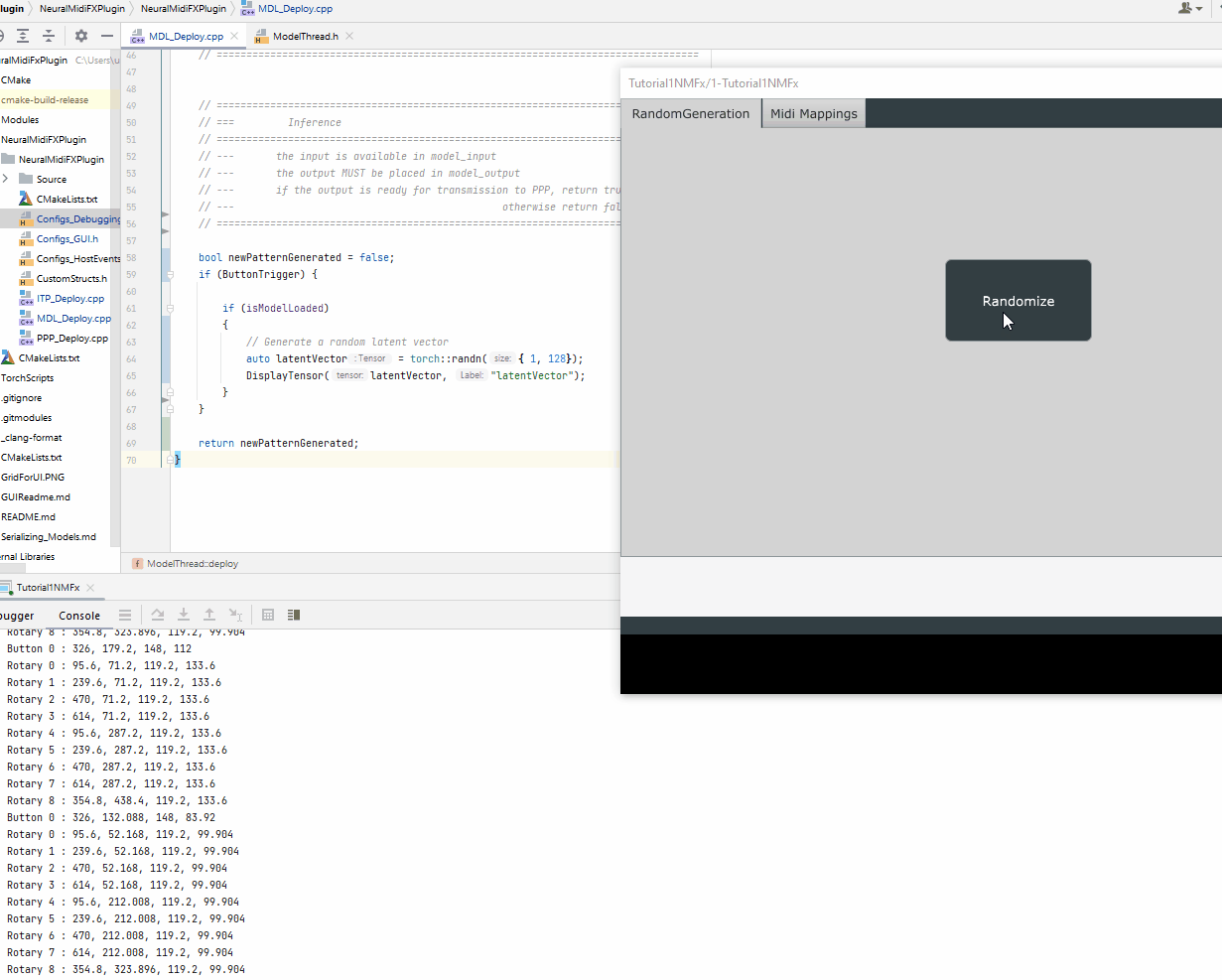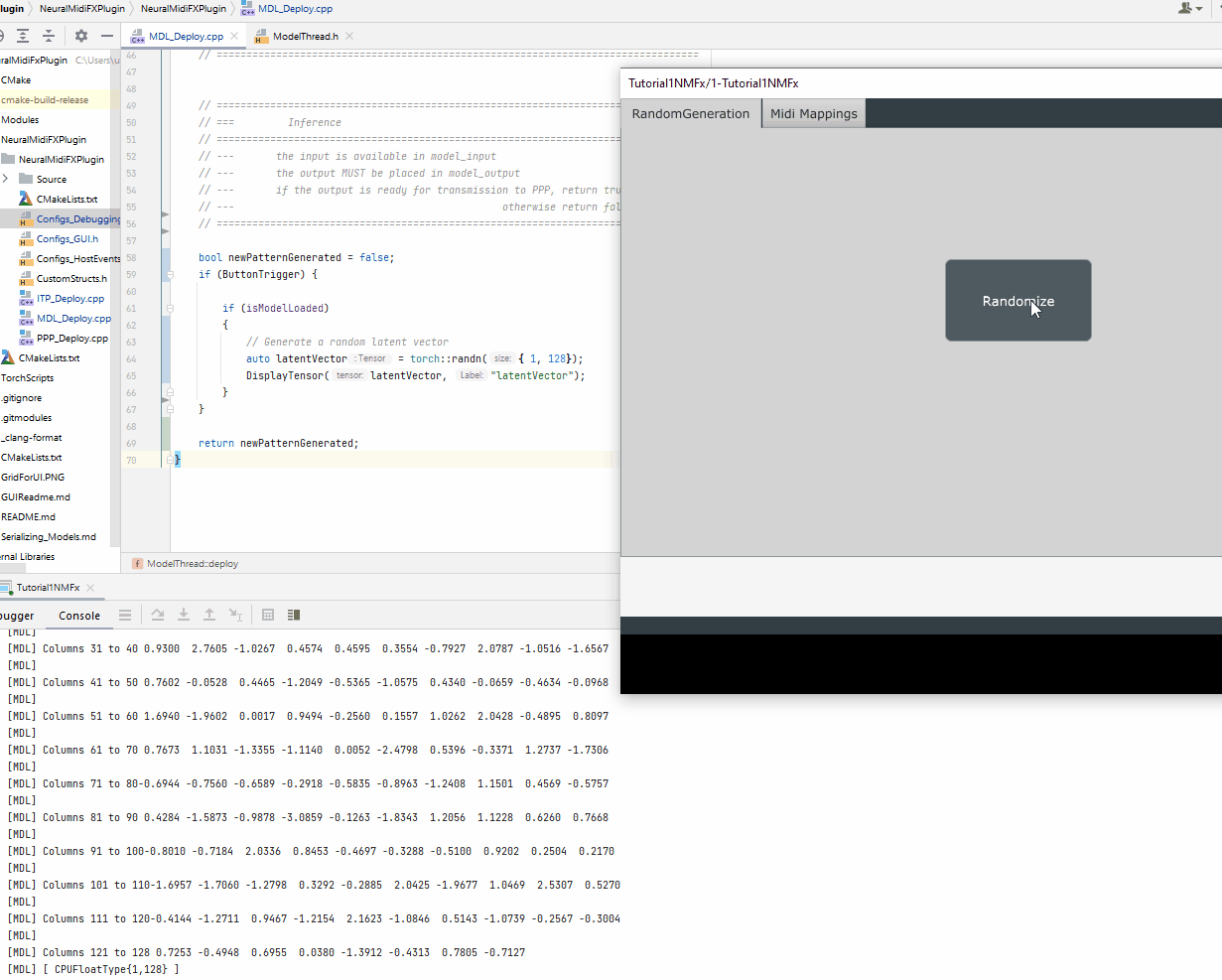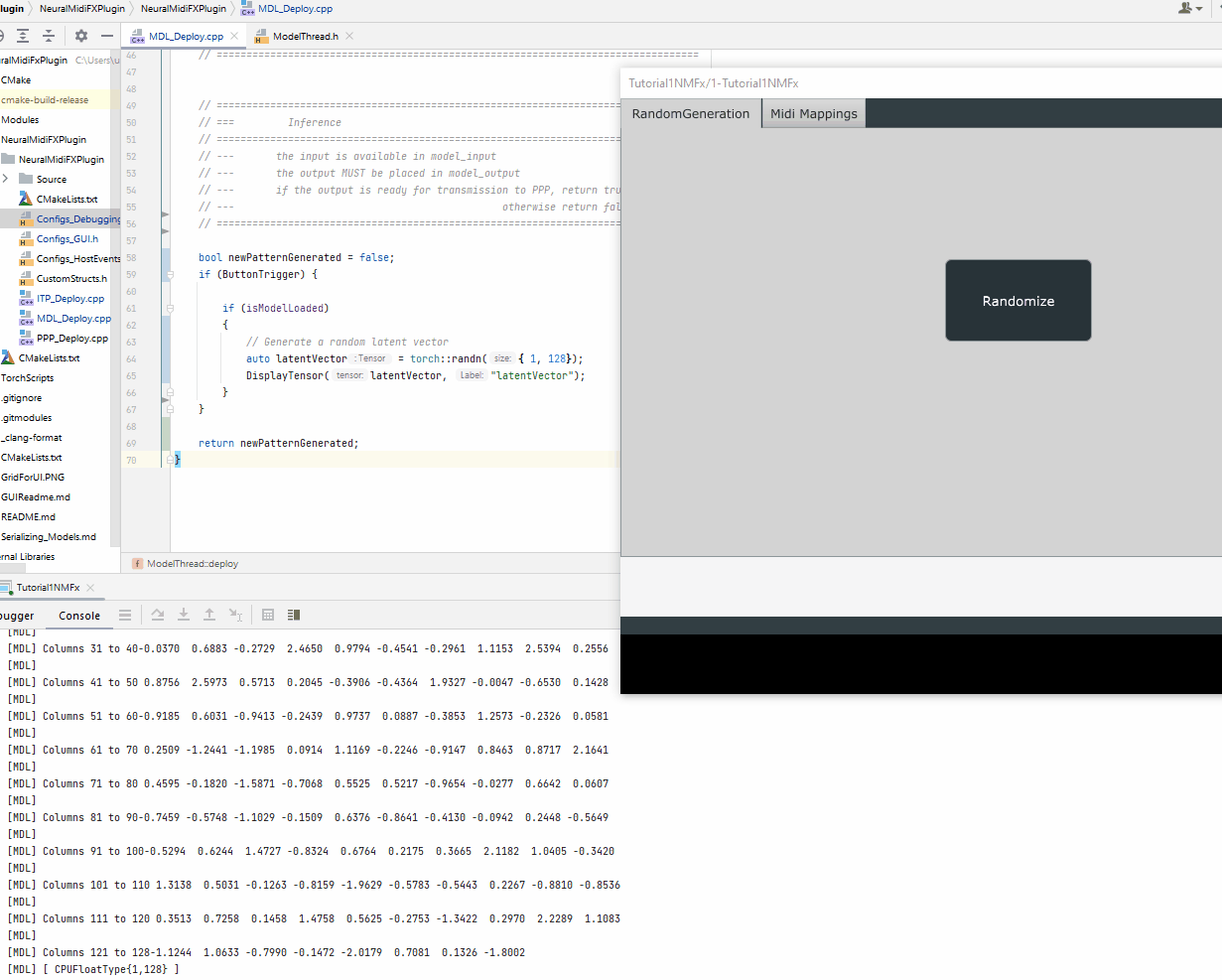
Once the latent vector is generated, we will need to prepare the other inputs to the model based on the interface of the scripted method, sample
// ModelThread::deploy() method in MDL_Deploy.cpp
// ...
bool newPatternGenerated = false;
if (ButtonTrigger) {
if (isModelLoaded)
{
// Generate a random latent vector
auto latentVector = torch::randn({ 1, 128});
// Prepare other inputs
auto voice_thresholds = torch::ones({9 }, torch::kFloat32) * 0.5f;
auto max_counts_allowed = torch::ones({9 }, torch::kFloat32) * 32;
int sampling_mode = 0;
float temperature = 1.0f;
}
}
return newPatternGenerated;
Inference
Now that all the inputs are ready, we need to add them one by one to a std::vector<torch::jit::IValue>. Then, we need to get the scripted sample method, and subsequently, run inference. Once finished, we can extract the relevant outputs returned from the method
// ModelThread::deploy() method in MDL_Deploy.cpp
// ...
bool newPatternGenerated = false;
if (ButtonTrigger) {
if (isModelLoaded)
{
// Generate a random latent vector
auto latentVector = torch::randn({ 1, 128});
// Prepare other inputs
auto voice_thresholds = torch::ones({9 }, torch::kFloat32) * 0.5f;
auto max_counts_allowed = torch::ones({9 }, torch::kFloat32) * 32;
int sampling_mode = 0;
float temperature = 1.0f;
// Prepare above for inference
std::vector<torch::jit::IValue> inputs;
inputs.emplace_back(latentVector);
inputs.emplace_back(voice_thresholds);
inputs.emplace_back(max_counts_allowed);
inputs.emplace_back(sampling_mode);
inputs.emplace_back(temperature);
// Get the scripted method
auto sample_method = model.get_method("sample");
// Run inference
auto output = sample_method(inputs);
// Extract the generated tensors from the output
auto hits = output.toTuple()->elements()[0].toTensor();
auto velocities = output.toTuple()->elements()[1].toTensor();
auto offsets = output.toTuple()->elements()[2].toTensor();
DisplayTensor(hits, "HITS");
}
}
return newPatternGenerated;
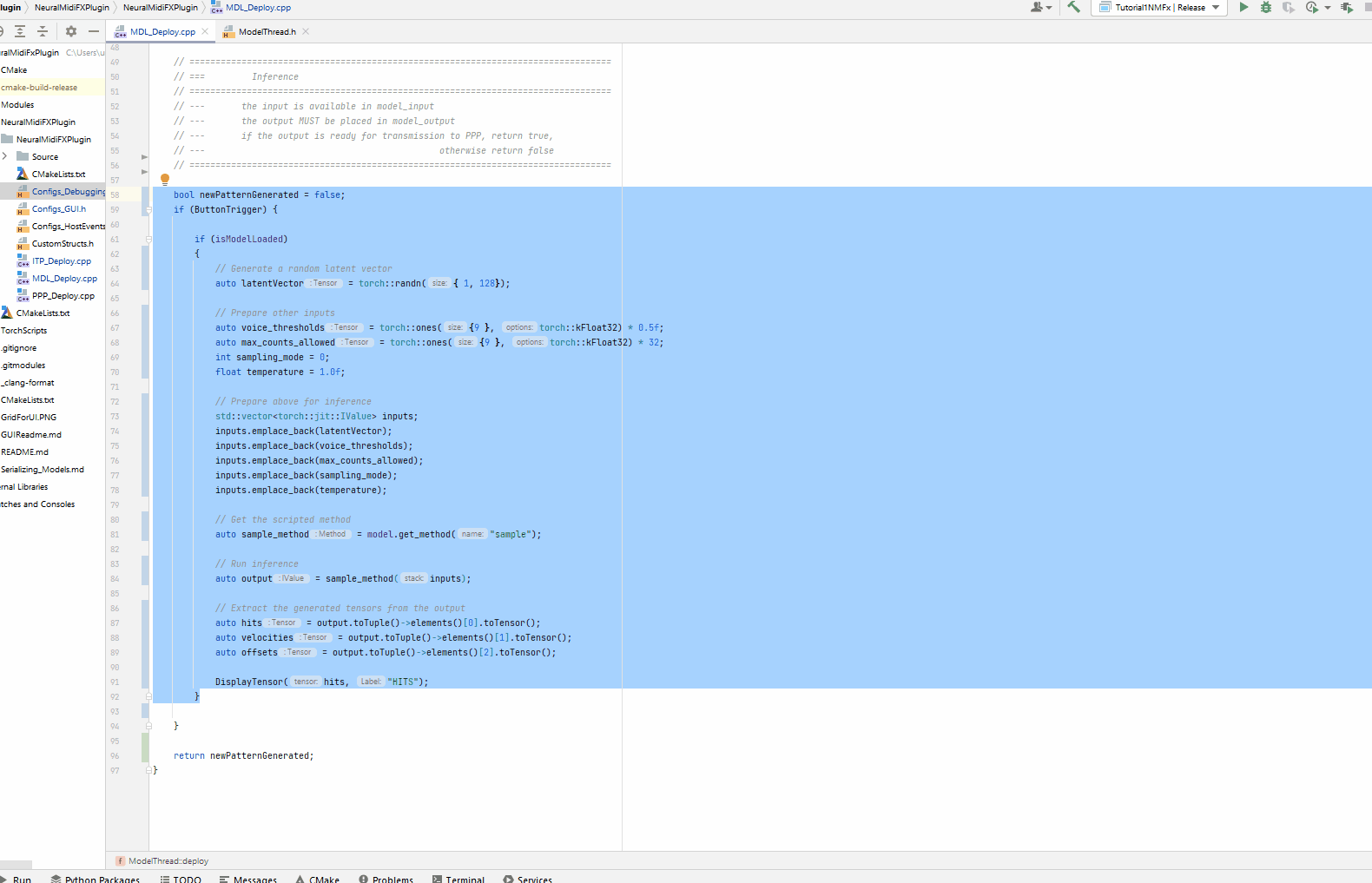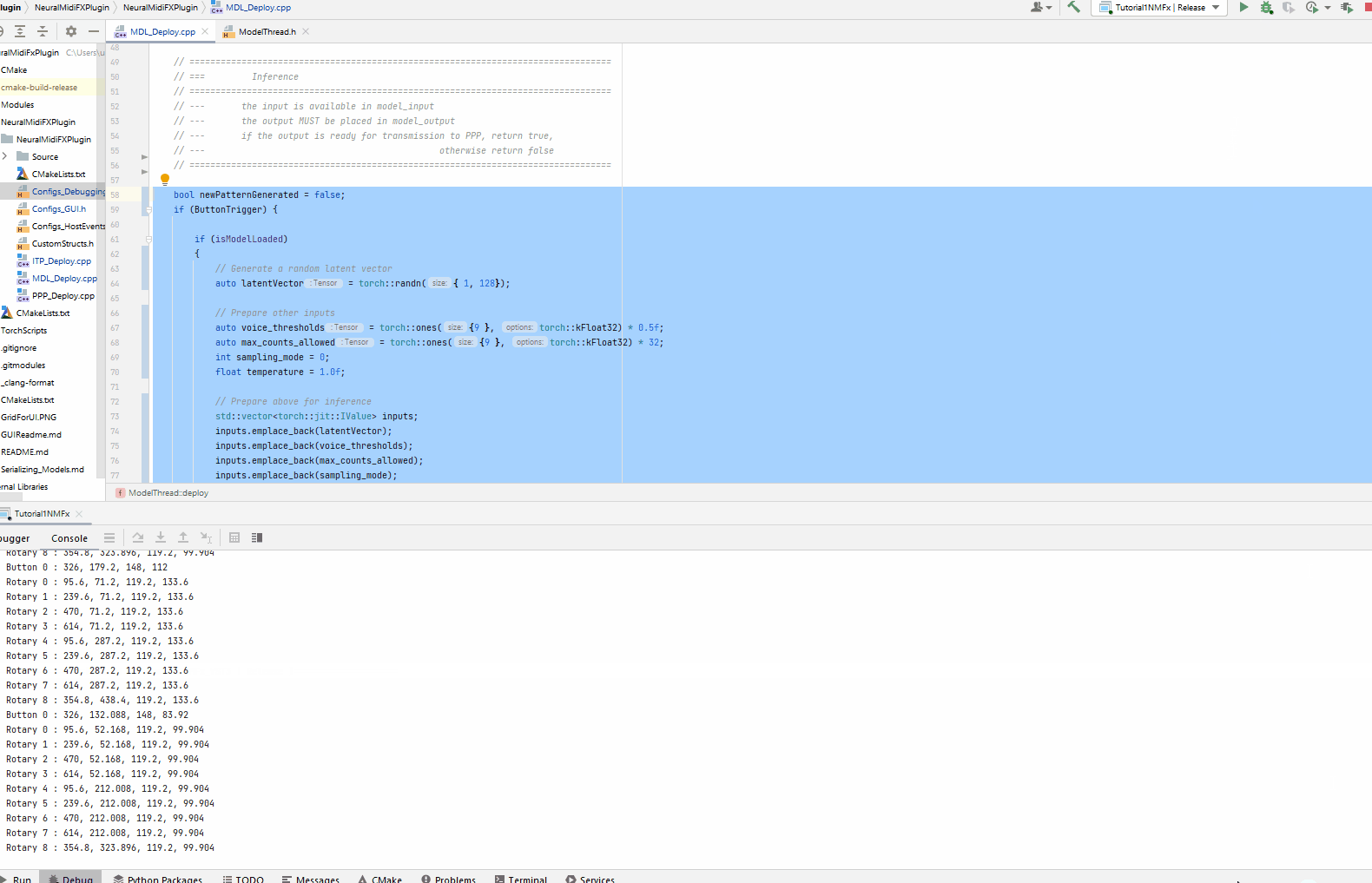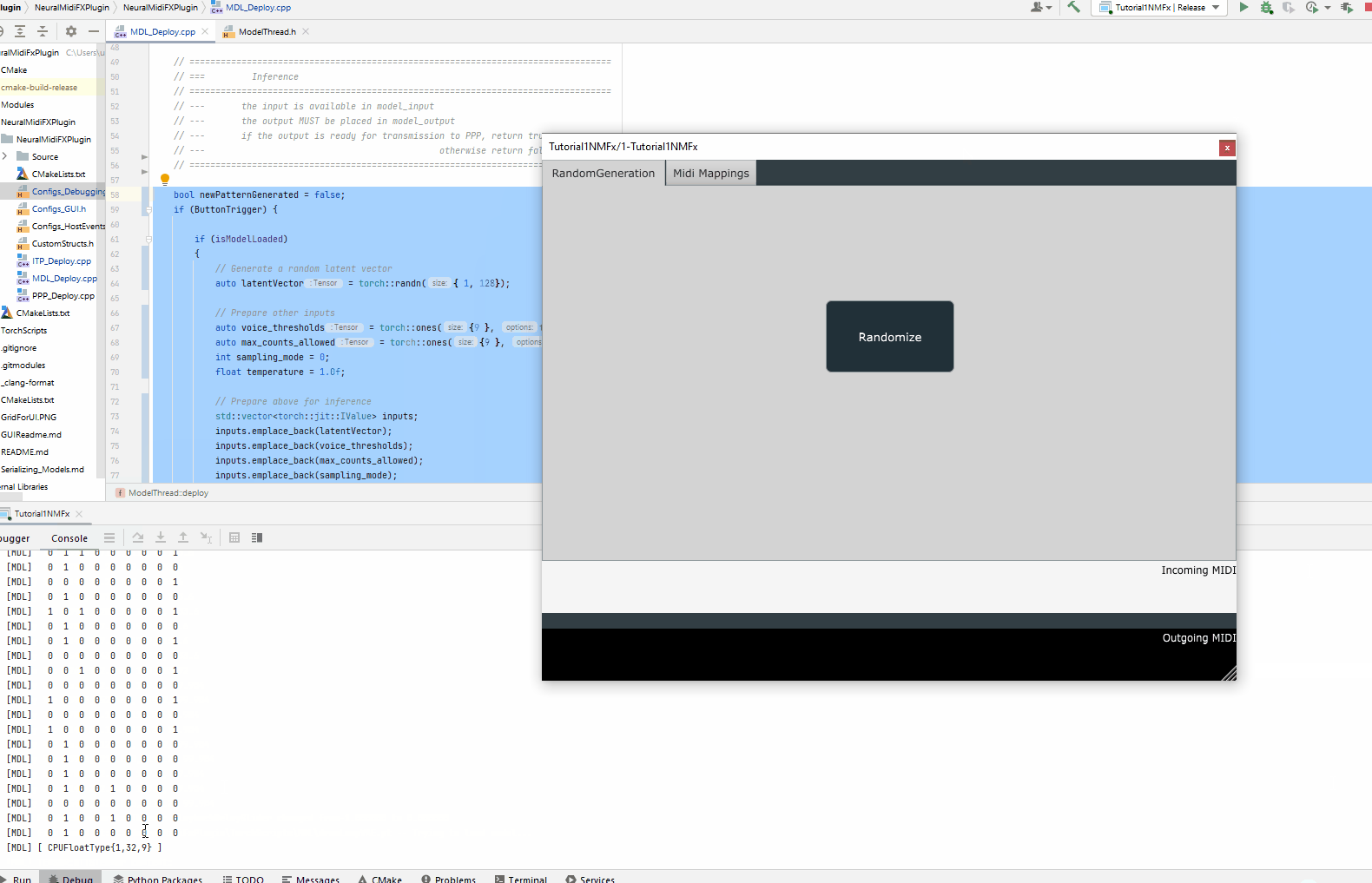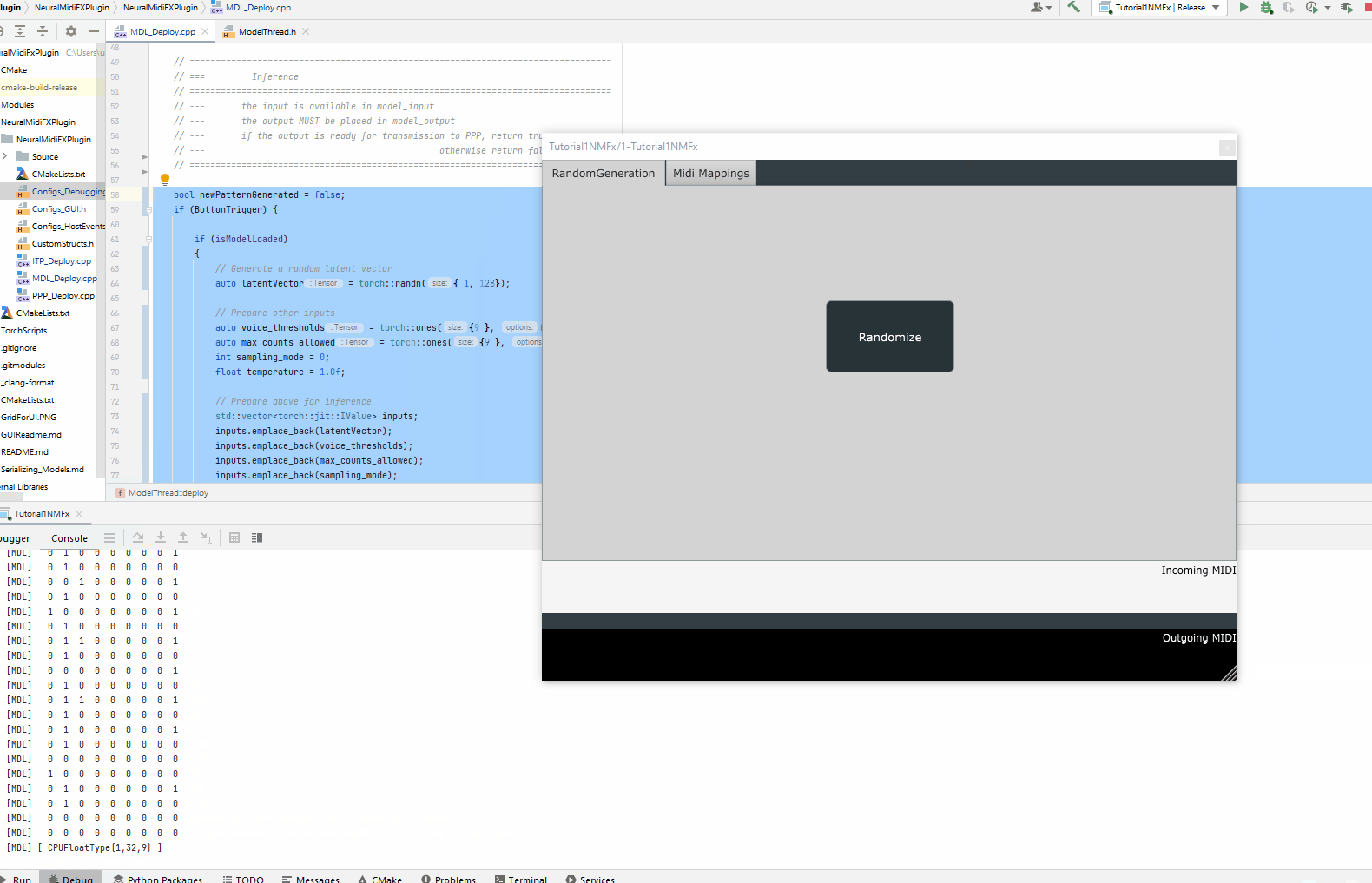
Wrapping the generated pattern in model_output
As mentioned in the documentation, the model_output is a structure that can be modified to pass any information from the ModelThread to the PlaybackPreparatorThread.
We will start with adding three tensor fields for the generated outputs hits, velocities, offsets to the model_output structure available in the CustomStructs.h file.
// ModelOutput struct in CustomStructs.h
struct ModelOutput {
torch::Tensor hits;
torch::Tensor velocities;
torch::Tensor offsets;
// ==============================================
// Don't Change Anything in the following section
// ==============================================
// used to measure the time it takes
// for a prepared instance to be
// sent to the next thread
chrono_timer timer{};
};
Once updated, we go back to the ModelThread::deploy() method and place the generations in the local instance of the ModelOutput struct. Subsequently, we set the newPatternGenerated flag to true, so as to notify the wrapper that the data is ready to be sent to the next thread.
// ModelThread::deploy() method in MDL_Deploy.cpp
// ...
// flag to indicate if a new pattern has been generated and is ready for transmission
// to the PPP thread
bool newPatternGenerated = false;
if (ButtonTrigger) {
if (isModelLoaded)
{
// ...
// wrap the generated tensors into a ModelOutput struct
model_output.hits = hits;
model_output.velocities = velocities;
model_output.offsets = offsets;
// Set the flag to true
newPatternGenerated = true;
}
}
return newPatternGenerated;
}
PlaybackPreparatorThread::deploy()
What we want to do in this method is to:
- Check if a new pattern has been generated by the
ModelThread - If yes, extract the notes and prepare the pattern for playback
- Send the prepared pattern to the wrapper
To learn more about the
PlaybackPreparatorThread, please refer to the documentation
Checking if a new pattern has been generated
We can check if a new generation has been received from the ModelThread by checking the new_model_output_received variable passed to the deploy() method.
// PlaybackPreparatorThread::deploy() method in PPP_Deploy.cpp
// =================================================================================
// === 1. Get the latest model generation (if available)
// =================================================================================
if (new_model_output_received)
{
PrintMessage("New Model Output Received");
}
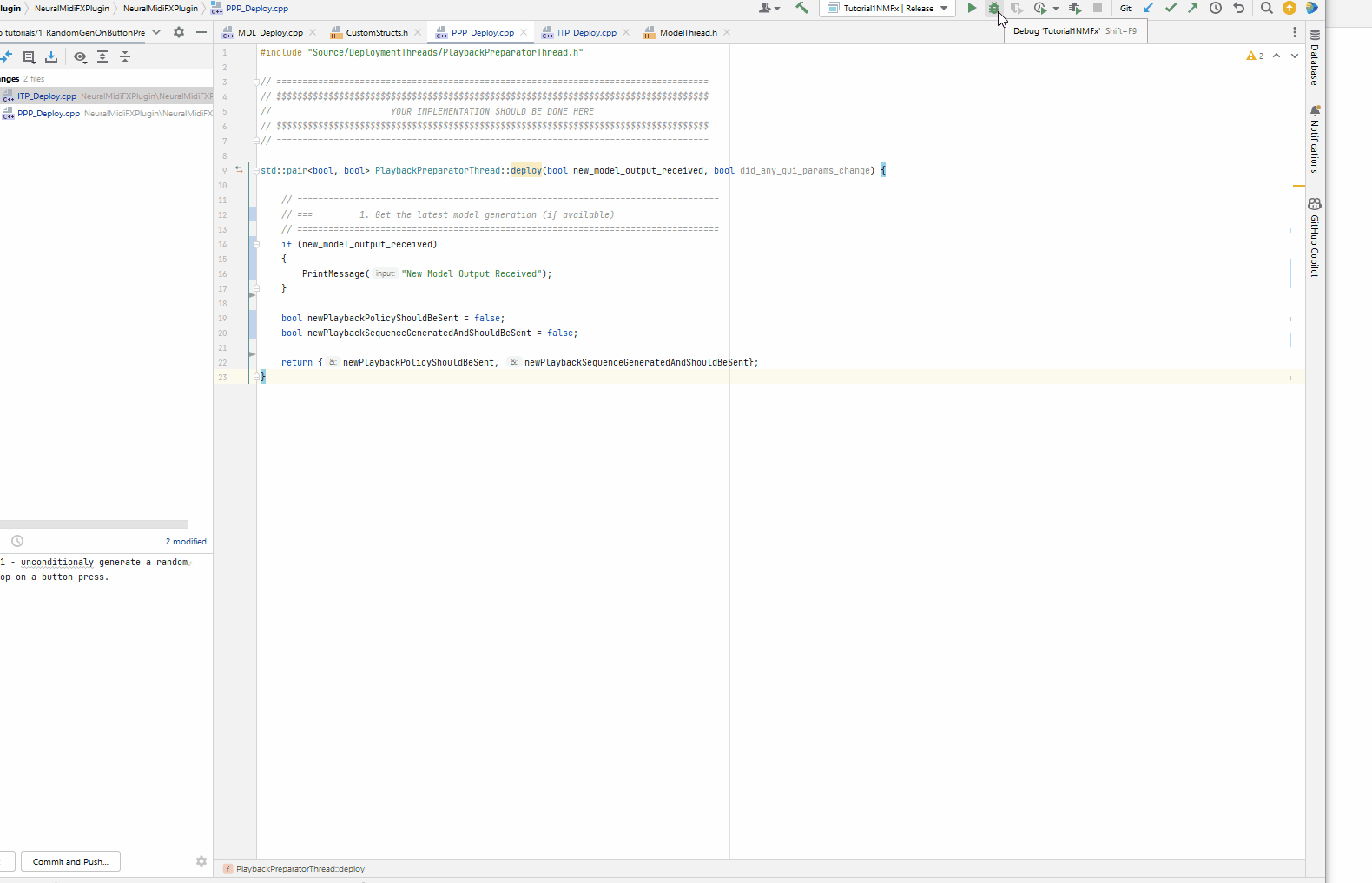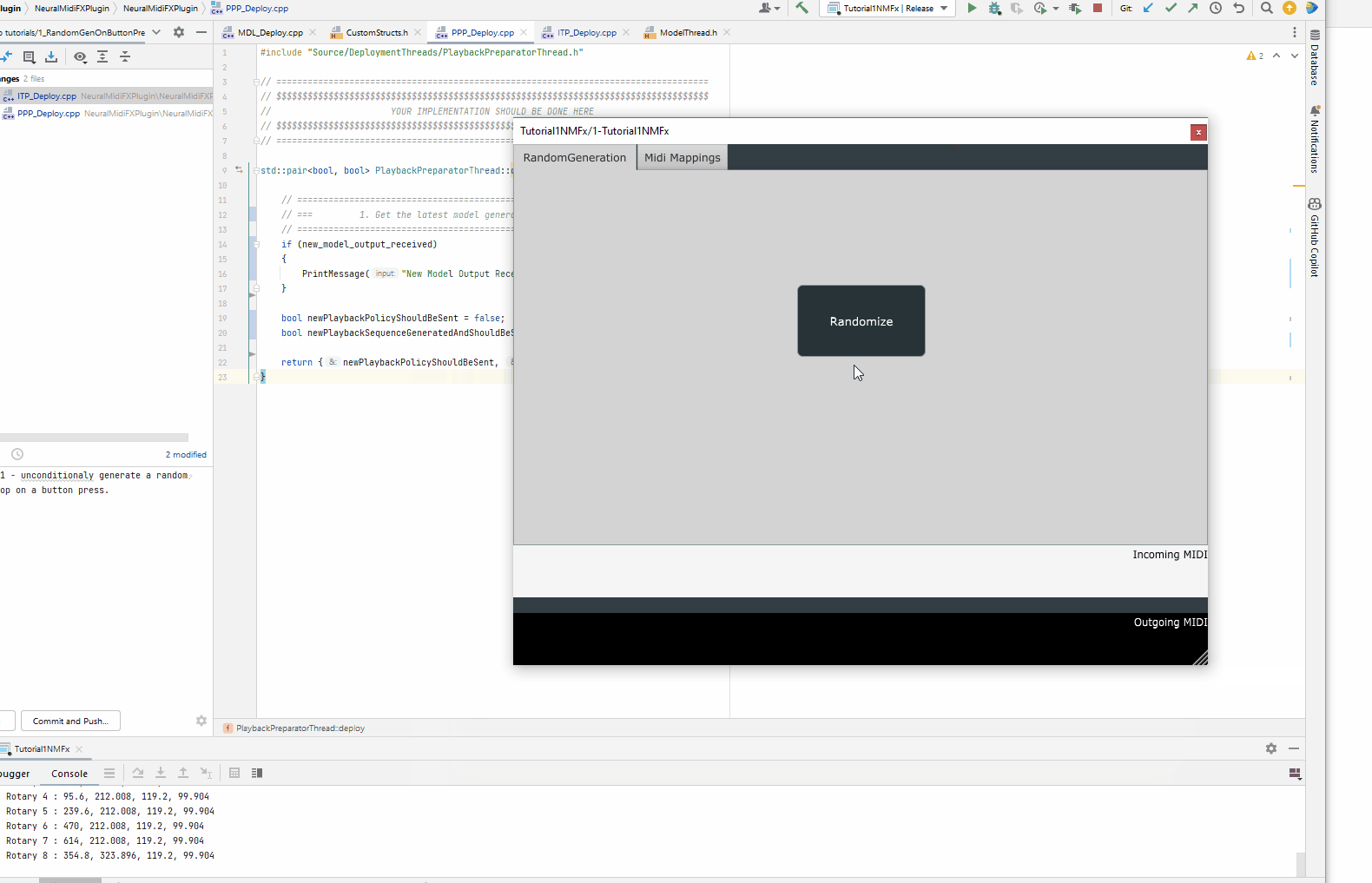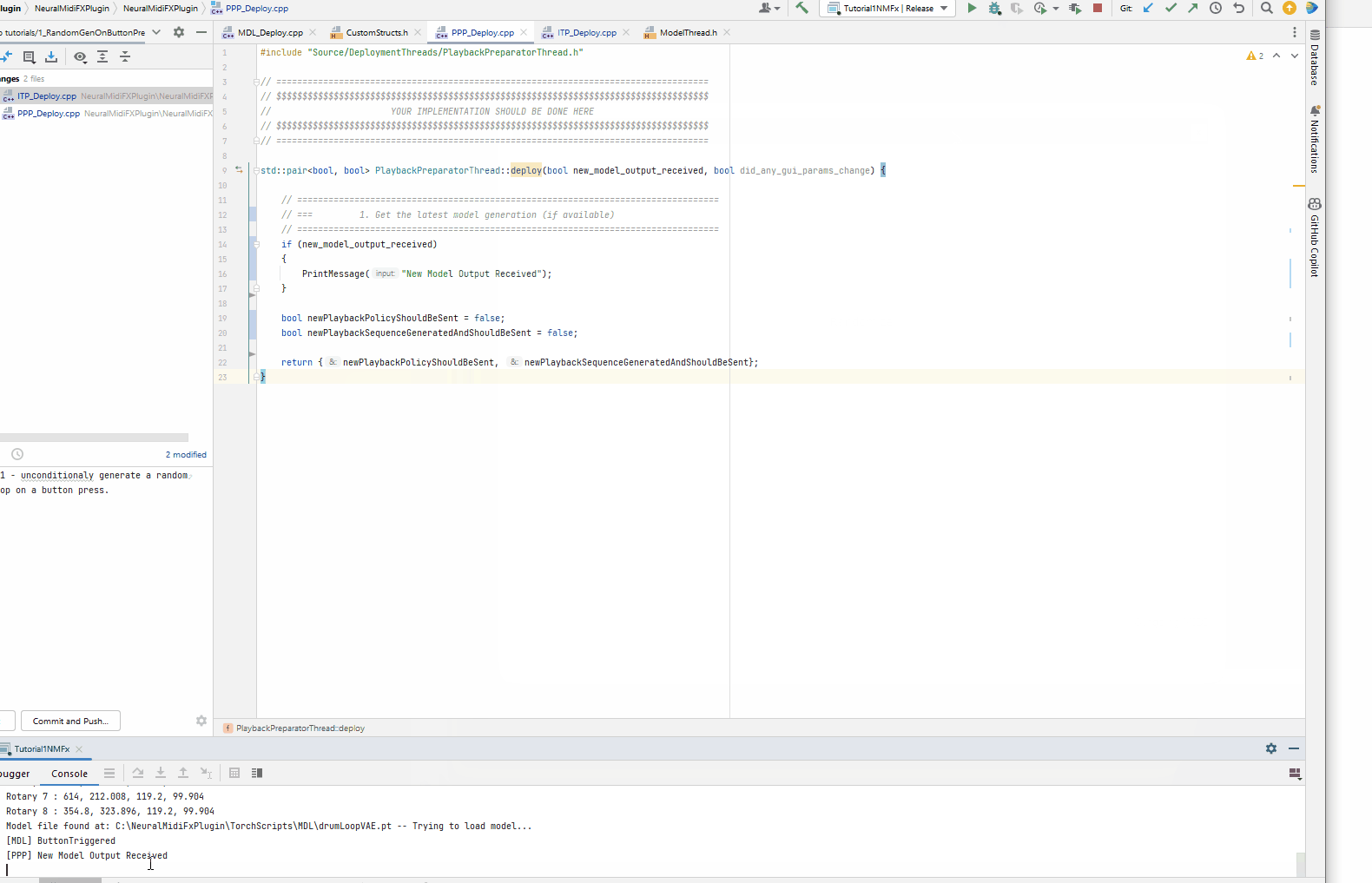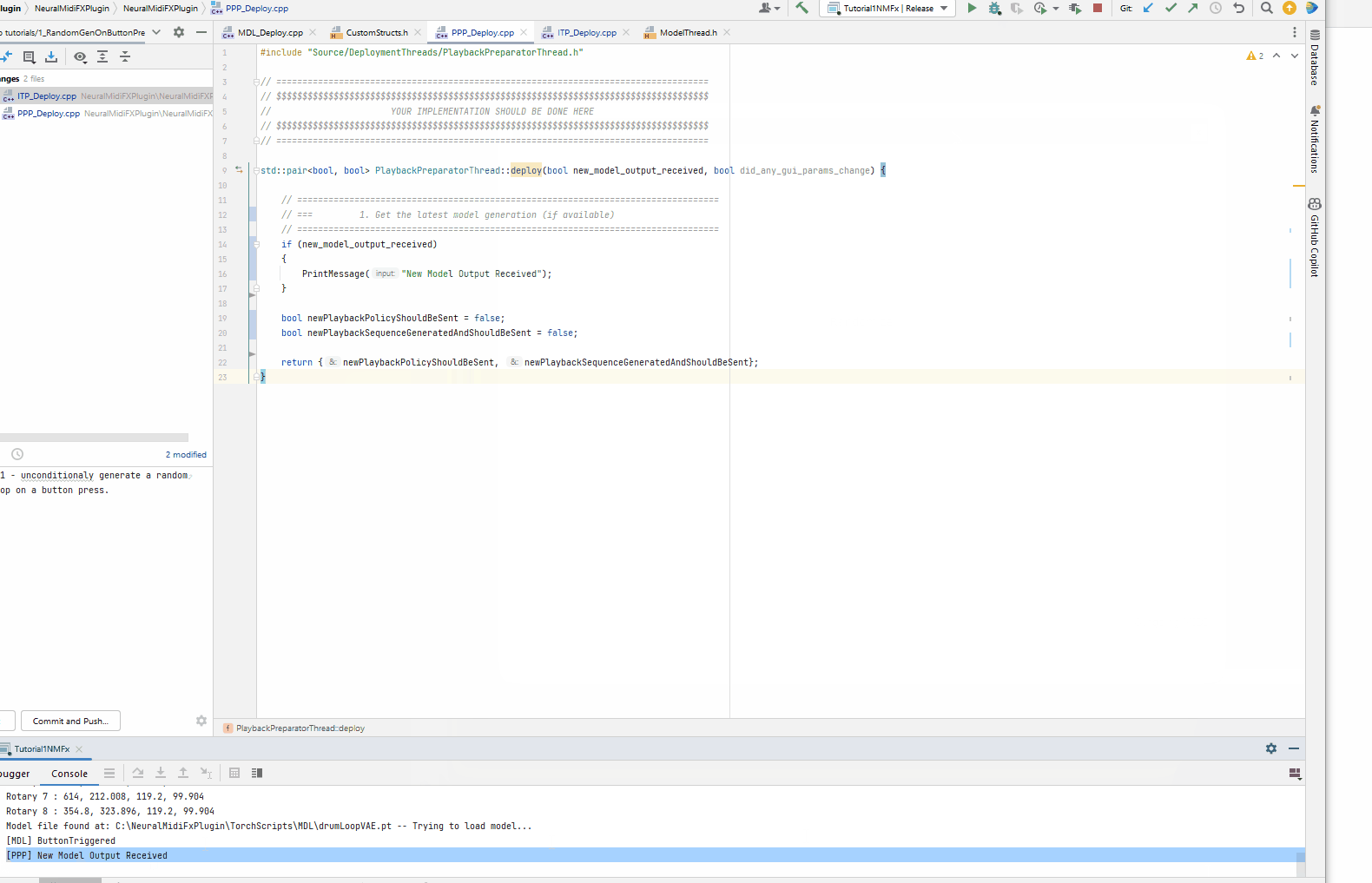
Extracting the notes and preparing the pattern for playback
First we will create a midi mapping based on the parameters in the second tab of the GUI.
// PlaybackPreparatorThread::deploy() method in PPP_Deploy.cpp
if (new_model_output_received)
{
// =================================================================================
// === 2. ACCESSING GUI PARAMETERS
// Refer to:
// https://neuralmidifx.github.io/docs/v1_0_0/datatypes/GuiParams#accessing-the-ui-parameters
// =================================================================================
std::map<int, int> voiceMap;
voiceMap[0] = int(gui_params.getValueFor("Kick"));
voiceMap[1] = int(gui_params.getValueFor("Snare"));
voiceMap[2] = int(gui_params.getValueFor("ClosedHat"));
voiceMap[3] = int(gui_params.getValueFor("OpenHat"));
voiceMap[4] = int(gui_params.getValueFor("LowTom"));
voiceMap[5] = int(gui_params.getValueFor("MidTom"));
voiceMap[6] = int(gui_params.getValueFor("HighTom"));
voiceMap[7] = int(gui_params.getValueFor("Crash"));
voiceMap[8] = int(gui_params.getValueFor("Ride"));
}
Then, we need to extract the notes from the generated tensors.
This model generates a pattern of 32 steps relative to a 16th note grid. Moreover, the offsets are relative to the gridlines ranging from -0.5 to 0.5. (-0.5 is a 32nd note before the gridline, 0.5 is a 32nd note after the gridline)
bool newPlaybackPolicyShouldBeSent = false;
bool newPlaybackSequenceGeneratedAndShouldBeSent = false;
// =================================================================================
// === 1. check if new model output is received
// =================================================================================
if (new_model_output_received || did_any_gui_params_change)
{
// =================================================================================
// === 2. ACCESSING GUI PARAMETERS
// Refer to:
// https://neuralmidifx.github.io/docs/v1_0_0/datatypes/GuiParams#accessing-the-ui-parameters
// =================================================================================
std::map<int, int> voiceMap;
voiceMap[0] = int(gui_params.getValueFor("Kick"));
voiceMap[1] = int(gui_params.getValueFor("Snare"));
voiceMap[2] = int(gui_params.getValueFor("ClosedHat"));
voiceMap[3] = int(gui_params.getValueFor("OpenHat"));
voiceMap[4] = int(gui_params.getValueFor("LowTom"));
voiceMap[5] = int(gui_params.getValueFor("MidTom"));
voiceMap[6] = int(gui_params.getValueFor("HighTom"));
voiceMap[7] = int(gui_params.getValueFor("Crash"));
voiceMap[8] = int(gui_params.getValueFor("Ride"));
PrintMessage("Here1");
if (new_model_output_received)
{
// =================================================================================
// === 3. Extract Notes from Model Output
// =================================================================================
auto hits = model_output.hits;
auto velocities = model_output.velocities;
auto offsets = model_output.offsets;
// print content of hits
std::stringstream ss;
ss << "Hits: ";
for (int i = 0; i < hits.sizes()[0]; i++)
{
for (int j = 0; j < hits.sizes()[1]; j++)
{
for (int k = 0; k < hits.sizes()[2]; k++)
{
if (hits[i][j][k].item<float>() > 0.5)
ss << "(" << i << ", " << j << ", " << k << ") ";
}
}
}
PrintMessage(ss.str());
if (!hits.sizes().empty()) // check if any hits are available
{
// clear playback sequence
playbackSequence.clear();
// set the flag to notify new playback sequence is generated
newPlaybackSequenceGeneratedAndShouldBeSent = true;
// iterate through all voices, and time steps
int batch_ix = 0;
for (int step_ix = 0; step_ix < 32; step_ix++)
{
for (int voice_ix = 0; voice_ix < 9; voice_ix++)
{
// check if the voice is active at this time step
if (hits[batch_ix][step_ix][voice_ix].item<float>() > 0.5)
{
auto midi_num = voiceMap[voice_ix];
auto velocity = velocities[batch_ix][step_ix][voice_ix].item<float>();
auto offset = offsets[batch_ix][step_ix][voice_ix].item<float>();
// we are going to convert the onset time to a ratio of quarter notes
auto time = (step_ix + offset) * 0.25f;
playbackSequence.addNoteWithDuration(
0, midi_num, velocity, time, 0.1f);
}
}
}
}
// Specify the playback policy
playbackPolicy.SetPlaybackPolicy_RelativeToAbsoluteZero();
playbackPolicy.SetTimeUnitIsPPQ();
playbackPolicy.SetOverwritePolicy_DeleteAllEventsInPreviousStreamAndUseNewStream(true);
playbackPolicy.ActivateLooping(8);
newPlaybackPolicyShouldBeSent = true;
}
}
return {newPlaybackPolicyShouldBeSent, newPlaybackSequenceGeneratedAndShouldBeSent};
}